物理世界的数据飞轮:分层视觉 AI 系统设计与优化

在物理 AI 落地中,连续视频流处理面临双重挑战:端侧算力瓶颈与长时序语义识别。为此,我们构建了一套分层视觉感知与推理级联系统。系统底层运行轻量视频编码器,实时进行异常初筛与事件定位;一旦检测到疑似风险,按需唤醒端侧 VLM 进行多模态验证,并通过本地数据飞轮实现双端的协同进化。
我们在智能家居安全检测集上验证了该系统。实验表明,分层级联架构突破了精度与能耗的双重瓶颈:相较于 MiniCPM-V-4.6 VLM 全量扫描 baseline(63.64% Recall,95.45% Precision),协同进化后的系统在保持 74.0% 低唤醒率(过滤掉 76.5% 的正常视频)的同时,将召回率(Recall)提升至 72.73%,精度(Precision)提升至 96.00%。系统在大幅节省端侧算力的前提下,实现了安全召回与检测精度的双重提升,为智能家居、工业、能源及具身感知场景的大规模边缘部署提供了高效的技术方案。
引言
随着多模态大模型、世界模型等技术的快速发展,人工智能正从数字世界走向物理世界。物理世界中时时刻刻都在产生海量的多模态数据,如果模型能够精准地理解这些物理数据并做出实时决策,将释放出巨大的产业价值。然而,在实际落地中,这些庞大的、不间断的数据流也给 Physical AI 系统带来了极其严苛的性能挑战。
想象一个典型的智能家居或工业巡检监控场景:一台高清摄像头每天 24 小时不间断地记录着环境视频。在大部分的时间里,画面中是正常的人员走动、角落睡觉的宠物,或是规律运行的工厂流水线。然而,真正需要系统发出警报、改变运行状态或请求人类关注和干预的,往往只有转瞬即逝的十几秒:
- 客厅里,老人与宠物嬉戏时突然受力失衡,重重滑倒在地板上,随后处于静止状态;
- 深夜的变电站门口,一个可疑的人影闪过,在触发感应灯后又慌忙折返逃离;
面对这些高价值、多样化的各类物理事件,多模态大语言模型(VLM)展现出了前所未有的语义理解与人机交互能力。VLM 能够回答更接近人类认知的问题:“画面中发生了什么危险情况?”、“小猫跳上沙发不需要关心,但跑进厨房就要告警”。
然而,如果我们直接将全量、实时的 24 小时视频流不间断地送入端侧 VLM,系统在实际部署时就会迅速崩溃:
- 算力与功耗限制:端侧硬件受限,全量运行大参数 VLM 会快速耗尽本地算力,整体功耗也将难以控制。
- Token 爆炸:处理长视频需要注入极高密度的视频帧 Token,极易超出端侧 VLM 的上下文窗口限制,算力需求也呈 N 平方增长。
- 时序感知局限:大多数端侧 VLM 擅长识别单帧的空间静态语义,但对物体运动的细粒度变化极其不敏感,容易产生严重的漏报;
这构成了一个根本性矛盾:VLM 具有极高的视觉语义理解上限,但直接将其用作连续扫描器在工程和经济上都是不可行的。
1. 从视觉感知模型到 VLM
尽管多模态大语言模型(VLM)极大地提升了视觉语义理解的上限,以 CLIP[1]、SigLIP[2] 为代表的视觉感知编码模型(Vision Encoder)在 Physical AIOS 的系统设计中依然发挥着不可替代的基石作用,并且自身也在不断进化。
基于轻量级神经网络(如 ViT、CNN)构建的 Vision Encoder 具有极低的计算时延与可控的功耗表现,适合作为端侧的常驻感知层。在这些感知层提取出的时序表征之上,系统可以外接轻量级的事件分类器,用来持续监控异常运动。在 Physical AIOS 中,感知模型不再承担最终的语义裁决,而是负责“候选发现”、“时间窗口定位”和“物理运动证据提取”,为下游 VLM 提供被大幅压缩的高价值输入切片。
当感知层捕获到疑似高危事件并唤醒 VLM 后,VLM 作为语义理解层提供以下三大能力提升:
- 开放场景理解:摒弃了传统分类器只能识别固定类别的限制,能够直接理解人类用自然语言定义的任意物理场景和复杂指令;
- 结构化推理:能够同时输出支持该判断的视觉证据,并给出不确定性评分,避免幻觉引发的无序报警;
- 自然语言交互:将用户的即时反馈(如“这是狗在玩耍,不是异常”)直接转化为自然语言 Prompt、判定规则或本地 Hard Cases,作为数据飞轮的更新动力。
通过将两者的系统边界清晰明确地划分为“感知层初筛候选”与“推理层语义验证”,系统实现了在低资源开销下逼近云端大模型语义理解上限的可能。以下我们将系统介绍这些不同类模型的特色和优势。
2. 核心模型与技术路线演进
2.1 视觉编码器 (Vision Encoder)
端侧视觉感知的第一步是将原始像素压缩为具有强表达力的语义表征。下表总结了五代代表性视觉编码器在架构与表征上的技术演进:
| 模型路线 | 核心损失 函数 | 视觉-文本对齐方式 | 教师网络更新 (EMA) | 多分辨率与宽高比支持 | 优势与作用 |
|---|---|---|---|---|---|
| CLIP (2021) | 全局 Softmax 损失 | 双塔端到端联合对比学习 | 无 | 仅固定正方形裁剪 | 提供基础的全局对比语义空间,做极粗粒度的开集初筛。 |
| SigLIP (2023) | Pairwise Sigmoid 损失 | 二分类对齐,算力与 Batch 解耦 | 无 | 仅固定正方形尺寸 | 摆脱了 All-Gather 通信瓶颈,提供更鲁棒的端侧小 Batch 对齐表征。 |
| SigLIP 2 (2025.02) | Sigmoid + LocCa 描述定位 + 自监督 | 端到端联合优化,引入生成辅助 | 全权重 EMA (全 Encoder 权重平滑) | NaFlex 变体,支持原生宽高比与动态序列长度 | 极大地增强了细粒度目标定位(Localization)与密集特征表示,是主流端侧 VLM 的首选感知底座。 |
| TIPSv2 (2026.04) | Sigmoid + LocCa + iBOT++(全 patch 监督损失) | 强化密集局部 patch-text 对齐 | Head-only EMA (仅投影头计算 EMA 更新) | 支持原生宽高比与动态尺寸 (NaFlex) | 在预训练中强力保住局部特征,使零样本语义分割和密集视觉证据对齐性能实现数倍提升。 |
| DINOv3 (2025.08) | DINO + iBOT + Gram Anchoring (相似度拓扑锚定) | 后置文本投影 (Post-hoc) | 全权重 EMA + 早期 Gram 教师 | 使用 RoPE 与 Box 抖动,支持混合分辨率 | 纯视觉自监督的巅峰。通过 Gram 锚定锁定局部特征的几何空间,提供最稳定、无文本偏置的密集深度与空间几何拓扑。 |
| InternVideo-Next (2025) | Encoder-Predictor-Decoder 解耦的时序自监督 | 视频-文本多模态对比对齐 | 全 Video Encoder 权重更新 | 支持可变长度与多尺度时序滑窗 | 时序世界模型的感知底座。专门捕捉运动轨迹、速度、因果关系和物理状态转移,负责生成 Top-k 异常时间窗。 |
CLIP[1:1] 由 OpenAI 提出,利用大规模图文对比学习,最早把图像和文本映射到同一语义空间,让“有猫”“有人跌倒”“门口有人停留”这类文本概念可以成为视觉检索和零样本分类的目标。SigLIP[2:1] 进一步把对比学习改造成成对 sigmoid loss,降低全局 softmax 对大 batch 和跨设备通信的依赖。SigLIP 2[3] 则把 captioning、self-distillation、masked prediction、native aspect ratio 等训练机制整合到同一套视觉语言 encoder 中,强化了 localization、dense features 和多语言能力。
Meta 的 DINOv3[4] 代表了另一条自监督学习路线。它不依赖文本对齐,而是以基于教师-学生网络(Teacher-Student)架构下的掩码图像建模(Masked Image Modeling)为核心自监督逻辑。在此基础上,DINOv3 在长程训练中引入了 Gram 锚定(Gram Anchoring)机制来约束 patch 级 dense 特征。该机制通过对齐当前特征图的 Gram 矩阵(表征局部 patch 间点对点相似度的二阶自相关拓扑关系)与早期高 dense 质量表征时期的教师网络 Gram 矩阵,有效锁定了视觉表征的局部空间结构与几何关联。
DeepMind 开发的 TIPSv2[5] 关心的是 patch-text alignment。普通图文对齐更擅长全局概念,比如“图里有狗”,但物理 AI 经常需要关注局部的动作,比如“孩子靠近台阶”“手接触危险区域”“包裹被拿走”。TIPSv2 通过 iBOT++ 和多粒度 caption sampling 强化 patch 与文本概念的对齐,让局部视觉证据更容易进入语言推理链路。
视频不是图片序列。物理事件常常藏在速度、顺序、轨迹、接触、持续静止和状态转移里。InternVideo-Next[6] 的意义在于:它不只是视频分类 encoder,而是把 predictor 放到 latent world model 的位置,通过 Encoder-Predictor-Decoder 框架学习更强的时序世界表征。对我们关注的场景来说,它适合承担长视频滑窗 embedding、候选事件召回、运动证据提取、risk head 和 event token 上游 latent,因此下文的实验将重点采用 InternVideo-Next 编码器。
2.2 多模态大语言模型 (Vision Language Models)
线上闭源 VLMs(如 Gemini 3.5[7]、GPT-5.5[8])拥有极高的智能水平,但在端侧多模态场景下,它们的劣势在于高昂 API 调用成本、较高的网络时延、持续视频流传输的带宽压力以及敏感的隐私安全性。在实际系统中,端侧 VLM 和云端 VLM 也可以联合使用:由端侧 VLM 以低成本、低时延,实时解决大部分问题,少量的 hard case 再回流到云端做进一步的判断和模型调优。
端侧多模态模型则以 Qwen3.5-VL[9]、Gemma 4[10] 和 MiniCPM-V-4.6[11] 为代表。其中 MiniCPM-V-4.6 在低参数量(如基于 Qwen3.5-0.8B[9:1] 与 SigLIP2-400M[3:1] 进行协同调优)下实现了极佳的性能和精度:支持 4-bit INT 量化,可轻松常驻于边缘 NPU 或边缘显存(消耗显存
2.3 物理世界模型 (Cosmos 3)
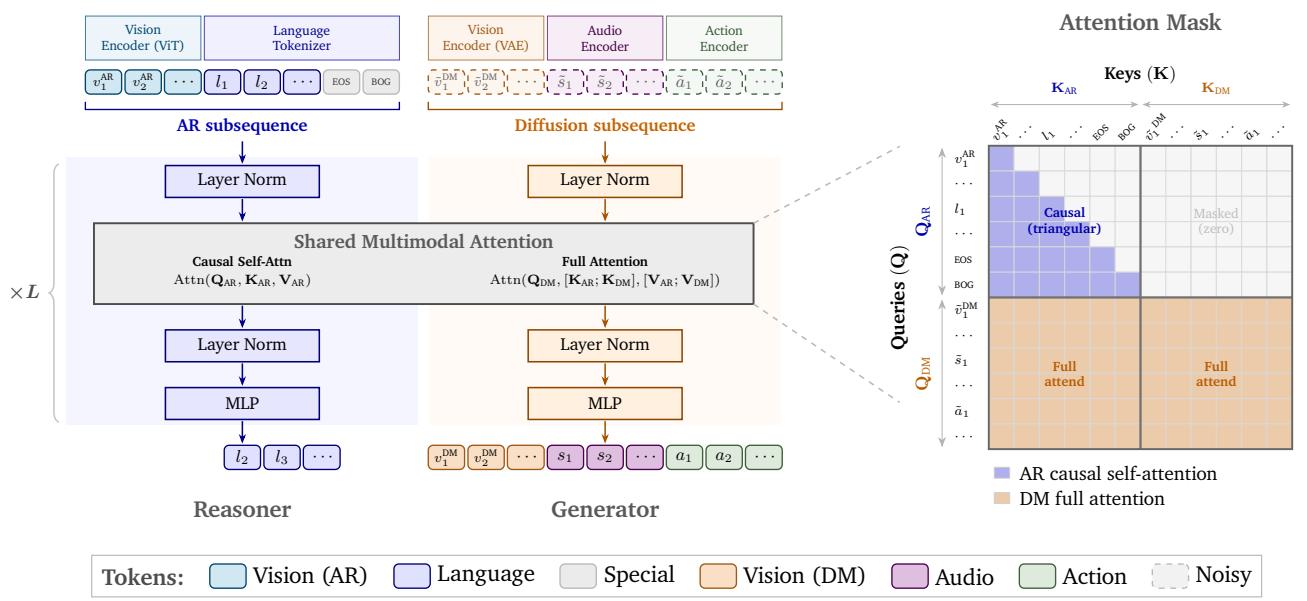
在物理 AI 领域,另一个快速发展的方向则是世界模型。NVIDIA 最近推出的 Cosmos 3[13] 将语言理解、视频生成、时序预测以及动作规划全部融入一个统一的全模态架构中:
- 双重编码机制:Cosmos 3 同时使用 ViT 理解编码器(负责高阶语义与认知推理)与视频 VAE 生成编码器(负责无损保留用于视频生成的物理细节);
- MoT (Mixture of Tokens) / Reasoner / Generator:通过在大规模物理仿真与现实视频上进行自监督预测,Cosmos 3 能够通过生成式“想象(Rollout)”来预测未来的物理世界走向,并据此调整机器人的动作。
然而,在边缘端部署 Cosmos 3 级别的全模态世界模型在当前算力下仍然是挑战重重,也并不能解决本文中提出的诸多实际挑战。因此,本文探讨的系统不是要复刻 Cosmos 3,而是聚焦于边缘端精准视觉理解这一关键子系统,探索如何将 Video Encoder 感知模型与端侧 VLM 组合成一个高效能、可反馈、易调优的视觉子系统。
3. 高效可靠的分层视觉系统
为了在端侧有限的硬件功耗与内存预算内实现极致的实时语义理解,我们设计了一套分层视觉感知与推理级联系统(如图 3.1 所示)。该系统在底层部署了一套 Always-On 低能耗感知流水线,在顶层辅以高智能的 On-demand 认知推理核验。这种设计不仅有效降低了端侧 VLM 的算力需求,还进一步大幅提升了整体系统精度,并具备了本地进化能力的自适应数据飞轮能力。
系统主要由以下四个模块协同运作:
- 前端感知层:系统的中 InternVideo-Next Encoder 负责对输入的连续视频帧提取长程时序特征;Event Classifier 基于轻量级决策边界对特征进行运动能谱与物理异常建模;Risk Router 采用特定的自适应策略判断当前是否有高危或异常物理动作发生,以极低功耗在前端过滤日常背景视频流(在测试集上成功过滤 76.5% 的正常视频),并在异常瞬间向认知推理层发送唤醒信号。
- 后端认知推理层:作为系统的认知内核,该层由 MiniCPM-V VLM 构成,只在收到唤醒信号时按需激活。它负责深度核验前端送来的候选视频切片语义,利用大模型的开放场景理解与多模态交互能力,梳理出结构化的逻辑证据链,最终输出高确定性的结构化决策 JSON。
- 策略决策与动作执行层:Policy Layer 负责融合业务逻辑、安全防线与地理围栏规则,做出警报分发或干预裁决;Actuator 执行具体告警推送,并将漏报、误报及低置信度等高价值 Hard Cases 送入本地 feedback 缓存,为数据进化积累弹药。
- 反馈自适应闭环:通过反馈收集与优化引擎,系统可在本地利用回流的 Hard Cases 样本离线优化前端 Video Encoder,并对端侧 VLM 的 LoRA 权重进行更新,实现两层系统的协同进化。
4. 家庭场景实验验证:感知模型与 VLM 分层优化的数据飞轮
为了验证系统在降低推理成本和提升精度上限上的可行性,我们在家庭安全评估数据集 smarthome-bench[14] 的完整视频流子集上进行了一系列实验。实验使用由 1017 段真实物理家居环境视频组成的数据集,其中 训练集 包含 869 段视频样本(占
所有实验环节(包括前端视频编码器 LoRA 微调以及下游 VLM 协同微调)均运行在 NVIDIA RTX PRO 6000 Blackwell GPU (96GB) 算力平台上。
4.1 实验结果
为了评估系统的优化效果,我们构建了五个递进的实验方案进行对比评估:
- S1: VLM Baseline:纯端侧 MiniCPM-V-4.6 VLM 长视频全量扫描基线(阶段 1);
- S2: Cascade Decision:引入未微调的 InternVideo-Next 作为门控初筛,VLM 按需唤醒(阶段 2);
- S3: Encoder Adaptation:通过 LoRA 微调前端视频编码器以抑制日常背景的常态激活(阶段 3);
- S4: Feature Fusion:对下游 VLM 进行协同 SFT,通过 Token 融合直接读取原始时序特征(阶段 4 - 支线 A);
- S5: Co-evolution:上游 Adapt 编码器特征与下游 VLM 进行双端协同对齐 SFT(阶段 4 - 支线 B)。

各方案在 Mini 测试集(共 50 个视频,含 33 段安全异常与 17 段正常生活视频)上的具体评估指标如下表所示:
| 实验方案 | 实验设计 | Precision | Recall | F1-Score | VLM 唤醒率 |
|---|---|---|---|---|---|
| S1: VLM Baseline | 纯端侧 MiniCPM-V 全量扫描 baseline,无前端感知初筛。 | 95.45% | 63.64% | 76.36% | 100.0% |
| S2: Cascade Decision | 引入未微调的 InternVideo-Next 与轻量 SVM 异常门控,VLM 进行按需唤醒。 | 88.89% | 72.73% | 80.00% | 48.0% |
| S3: Encoder Adaptation | 对前端 Video Encoder 顶层进行 LoRA 适配微调以抑制背景误唤醒,下游 VLM 保持未微调。 | 87.10% | 81.82% | 84.38% | 72.0% |
| S4: Feature Fusion | 引入 Event-Token 投影层,将未微调的原始时序特征与下游 VLM 进行协同 SFT 微调。 | 88.46% | 69.70% | 77.97% | 80.0% |
| S5: Co-evolution | 前端微调后的 Encoder 结合后端 VLM 进行双端协同对齐微调和协同优化 | 96.00% | 72.73% | 82.76% | 74.0% |
4.2 分阶段实验分析
4.2.1 S1 到 S2:从全量扫描到门控初筛
在 S1 阶段,虽然纯 VLM 实现了 95.45% 的 Precision,但其 Recall 仅为 63.64%,漏报了 12 个真实安全隐患(包含婴儿车滑落和夜间潜入)。这是因为静态 VLM 对细粒度时序运动和渐变相对位移极度不敏感。同时,全量持续运行 VLM 带来了不可承受的算力功耗开销。
在 S2 阶段,我们设计了基于冻结 InternVideo-Next 编码器的 Multi-Chunk 级联系统。前端构建轻量级 SVM 门控分类器进行运动能谱建模与异常初筛。当门控得分
4.2.2 S3:视觉感知 LoRA 微调
在 S3 阶段 (Encoder Adaptation),为了压低日常家居常规晃动、宠物跑动等引起的误唤醒,我们对上游视频编码器的顶层 8 个 Attention 块进行了 LoRA 适配微调。
实验中,门控敏锐度得到提升,系统安全召回率升至历史最高的 81.82%。然而,由于仅有上游编码器进行了微调,下游多模态大模型(VLM)依然是未适配的 Zero-shot 提示词模型。在直接读取经微调的编码器空间特征时,下游 VLM 发生了明显的特征空间偏移与对齐失真。这导致系统的误警数反弹至 4个(Precision 降至 87.10%),且大模型复核的唤醒率回弹到了 72.0%。
4.2.3 S4:两级特征融合
在 S4 阶段 (Feature Fusion),为了解决下游大模型在时序动作维度的感知盲区,我们引入了特征级 Token 融合。设计了 Event-Token 投影层(在缺失特征时引入可学习的多模态占位 token 进行填充),将 8-slot event tokens 作为物理时序证据直接注入 VLM。
在此阶段,我们采用未微调的原始特征与下游 VLM 进行协同 SFT,并诊断修复了“Prompt-Target 不对齐”引入的数据冲突。然而,受限于上游特征未做适配,其 Recall 表现回落至 69.70%,且唤醒率上升到 80.0%。
4.2.4 S5:感知与推理的双端协同进化
在 S5 阶段 (Co-evolution),我们在特征融合的基础上,实现了上游适配特征与下游大模型的双端协同微调。在微调的前端 Encoder 基础上,对下游 VLM 的本地 LoRA 权重进行协同对齐训练,消除了特征偏移的负面影响。
结果表明,双端协同微调的 S5 方案 在保持 74.0% 唤醒率(在测试集上成功拦截并过滤了 76.5% 的正常视频,仅有 4 段正常视频被误唤醒送入 VLM,从而节省了 26% 的算力开销)的前提下,系统将安全异常的召回率(Recall)提升至 72.73%,相比 S1 基线(63.64%)高出 9.09 个百分点。 更为关键的是,S5 误警数量被极大压缩:在 Alert_or_Review 决策维度上,误警数缩减至 1 个,Precision 推高至 96.00%;而在 Alert(直接报警)维度上更是实现了 0 误警 (100% Precision)。这彻底解决了 S3 阶段由于单向微调导致的误警反弹问题,实现了安全高召回与高精度检测的兼顾。
4.3 典型场景行为与实证分析
为了提供直观的物理说服力,我们从测试集中挑选了 6 个代表性 Case 进行深入剖析,并展示其在不同演进阶段的决策路径与实证大图:
4.3.1 🚨 Case A:婴儿车滑落风险
- 场景画面(
smarthome_0001):前廊处,女子在开门时将推车短时间留在身后,婴儿车由于惯性开始缓慢倒退下台阶,并加速滑入旁边斜坡草坪,险些酿成侧翻事故。 - 系统表现:在纯 VLM 模式下,大模型受限于降采样后的静态帧,无法建立连续的运动关联,将其误判为“普通推车经过”,导致漏警(FN)。而在 S5 双端协同进化系统下,时序 Event-Tokens 的注入提供了连贯的位移轨迹,大模型敏锐抓住了婴儿车失控后溜的物理趋势,在第一阶段由门控触发唤醒后,决策判定为
Review进行兜底,成功防范了潜在险情。
4.3.2 🚨 Case B:夜间美洲狮侵入前院
- 场景画面(
smarthome_0028):深夜红外模式下,一只美洲狮(cougar)从右侧阴影中缓缓踱步走上门廊,随后朝大门嗅闻。 - 系统表现:在纯 VLM 模式下,面对夜间红外镜头的低对比度以及细微动作,大模型产生了漏检。在 S5 系统下,经过微调后的上游视频编码器对夜间低对比度运动表征极其敏锐,瞬时输出高激活信号唤醒下游大模型。VLM 结合 Event-Tokens 的连贯时序表征与身形特征,精准做出
pet_anomaly级别的Alert报警,成功将危险御于门外。
4.3.3 🚨 Case C:夜间门廊偷窃未遂
- 场景画面(
smarthome_0082):夜间,一名行迹可疑的人影弓着身子悄悄接近走廊内的露天桌椅企图偷窃,被突然亮起的感应灯晃照后慌乱折返逃跑。 - 系统表现:在纯 VLM 模式下,由于嫌疑人行动迅速且伴有夜间晃照的模糊残影,静态采样极易失焦导致漏警。S5 协同进化系统凭借 Adapted Encoder 对时序突变及剧烈掉头位移的捕获(Event-Tokens 的位移向量发生突变),在低功耗阶段准确检测出异常并唤醒下游,最终 VLM 结合上下文语义给出
Alert报警,成功捞回漏警。
4.3.4 🚨 Case D:室内摔倒风险
- 场景画面(
smarthome_0021):男子在客厅与大型犬拔河拉扯时用力过猛向后摔倒,跌在地板上并静止了数秒。 - 系统表现:在纯 VLM 模式下,大模型缺乏对重力加速度与惯性运动的理解,极易将该姿势判定为“与宠物趴在地上玩耍”的日常
Normal场景(导致漏警)。在 S5 系统下,上游门控凭借摔倒瞬间极其剧烈的运动特征给出高分(门控得分 0.945),唤醒后端 VLM。大模型读取 Event-Tokens 中跌倒前后的重心突变语义,精准识别出人体失去平衡并处于长时静止的状态,最终在Review决策维度输出人工介入告警。
4.3.5 💡 Case E:儿童独自骑车驶离监控边界
- 场景画面(
smarthome_0162):小男孩在没有成人监护的院前车道上骑车,逐渐驶离摄像头的防区。 - 系统表现:该样本在 S1 基线及 S5 等配置下均产生了漏报(判为
normal_home)。原因在于画面中男孩的骑行运动能谱高度平滑,并没有发生“跌倒”、“碰撞”或“侵入”等强烈的物理级动作突变,前端感知层未打出高危得分。然而,该场景的本质风险在于 “儿童独自越过了安全防区界限”,非物理动作异常,后续需要在产品方面引入相关规则判定改进。
5. 应用场景:家居、工业能源、具身智能
这套分层感知与数据飞轮架构,不仅在智能家居中得到了验证,还可以推广至工业能源、具身智能等关键的物理世界 AI 应用场景。
5.1 智能家居
智能家居是端侧分层闭环最为完美的落地场景之一。例如在该领域的先锋企业 Liko.ai(其将家庭智能硬件定位为“家庭场景里的端侧感知-理解-记忆-行动系统”[15]),其产品核心在于将家庭视频流从单纯的“录像工具”升级为具备持续学习能力的“家庭 AI 中枢”,覆盖了家庭安全、老人及儿童看护、日常寻物以及高光时刻记录等高价值、高频次场景。
在这些场景中,视频数据量极大但高价值事件稀疏,且用户对隐私保护有着极高的要求。分层系统的核心价值就在于:在确保“数据不出设备”的隐私安全边界下,前端感知模型以极低功耗对视频流进行持续巡检与异常初筛,只在发生“疑似高危”或“高光时刻”等特定事件时才间歇性唤醒端侧 VLM。通过“看见-理解-预警-交互-回流”的本地数据飞轮,系统得以逐步理解一个家特有的正常生活动线,在本地完成从被动记录到主动协同的智能跃升。
5.2 工业能源
在工业生产、输电检修等工业能源场景中,AI 系统面对的是高责任边界的极端环境。典型高危事件包括:工人违规越界、防护劳保缺失、设备局部异常升温、叉车与人员危险逼近、输电线路异物等。
在这些场景下,网络连接往往不稳定,且企业数据严禁出厂。分层系统的后端 Policy Layer 可以深度叠加工业工艺安全规则(如“在行车运行期间,下方 5 米内强行禁入”)。通过将 VLM 提取的结构化语义证据与工业安全 Rule Verifier 强绑定,整个系统可以作为一个可审计、高确定性的边缘安全运行时,在断网状态下实现高精度的安全闭环控制。
5.3 具身智能
对于移动机器人或机械臂控制等具身智能任务,其终极架构更倾向于 Cosmos 3 这种统一视觉、触觉、未来预测与控制动作的 World-Action Model(WAM)。但在多卡并行控制和实际部署中,直接计算高维度生成的算力开销是巨大的。
本文提出的方案在具身智能任务中可以作为高效的端侧视觉感知子系统:当物理环境中发生突发异常、受阻或检测到高价值交互契机时,底层的 Always-on 感知模块能够进行高效定位,并精准提取时序运动特征去提示并唤醒上游的 WAM 进行深度物理推理与交互动作重规划。我们预期,随着机器人落地推广和算法架构的演进,这种低功耗感知初筛与高阶认知推理分层的联合优化方法,将广泛融入到新一代的具身智能技术栈中。
6. 小结
如果说大语言模型的操作系统(如 Claude Code, Codex)管理的是文本 Token、外部工具与推理轨迹;那么物理世界的操作系统(Physical AIOS)管理的就是连续传感器流、物理事件 proposal、高风险决策控制以及反馈自适应机制。基于现实世界海量数据与复杂性、边缘端的算力与功耗限制等,这个领域还有诸多待解决的技术挑战。而本文提出视觉感知的分层优化与系统演进,实现了 Vision Encoder 和 VLM 的协同优化,给边缘端等物理 AI 场景提供了更加高效、可靠的技术方案。
References
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. "Learning Transferable Visual Models From Natural Language Supervision." ICML, 2021. ↩︎ ↩︎
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, et al. "Sigmoid Loss for Language-Image Pre-training." ICCV, 2023. ↩︎ ↩︎
Michael Tschannen, Alexey Gritsenko, Xiao Wang, et al. "SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features." arXiv:2502.05477, 2025. ↩︎ ↩︎
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, et al. "DINOv3: Self-Supervised Visual Representation Learning at Scale." arXiv:2508.12030, 2025. ↩︎
DeepMind. "TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment." Technical Report, 2026. ↩︎
Chenting Wang, Yuhan Zhu, Yicheng Xu, et al. "InternVideo-Next: Towards World Understanding Video Models." arXiv:2512.01342, 2025. ↩︎
Google Gemini Team. "Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context." Google Technical Report, 2024. See also Google Blog: "Introducing Gemini 3.5". ↩︎
OpenAI. "GPT-5.5 System Card." OpenAI Technical Report, 2026. ↩︎
Qwen Team. "Qwen3-VL Technical Report." arXiv:2511.08234, 2025. ↩︎ ↩︎
Merve Noyan, Pedro Cuenca, Sergio Paniego, et al. "Welcome Gemma 4: Frontier Multimodal Intelligence on Device." Hugging Face Blog, 2026. ↩︎
OpenBMB. "MiniCPM-V-4.6: Technical Report and Multimodal Computational Analysis." OpenBMB Repository, 2026. ↩︎
Kechen Fang, Yihua Qin, Chongyi Wang, et al. "LLaVA-UHD v4: What Makes Efficient Visual Encoding in MLLMs?" DeepMind Technical Report, arXiv:2604.14812, 2026. ↩︎
NVIDIA. "Cosmos 3: Architecture, Compute and Generative World Models." NVIDIA Technical Report, 2026. ↩︎
Xinyi Zhao, Congjing Zhang, Pei Guo, et al. "SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes." CVPR Workshops, 2025. ↩︎
Liko.ai. "Liko.ai: Edge AI Home Security and Smart Home System." 2026. ↩︎