The Physical World Data Flywheel: Hierarchical Vision AI System Design and Optimization

Deploying physical AI systems to process continuous video streams faces a dual challenge: edge computing bottlenecks and long-horizon temporal semantic recognition. To address this, we build a hierarchical vision perception and reasoning cascade system. The system runs a lightweight video encoder at the bottom layer for real-time anomaly screening and event localization; once a potential risk is detected, it triggers an on-device VLM for multimodal verification, while a local data flywheel enables co-evolution of both layers.
We evaluated the system on a smart home security detection dataset. The experiments demonstrate that the hierarchical cascade architecture overcomes the precision-energy consumption bottleneck: compared to the baseline of scanning all frames using the MiniCPM-V-4.6 VLM (63.64% Recall, 95.45% Precision), our co-evolved system maintains a 74.0% low wake-up rate (filtering out 76.5% of normal videos) while improving the Recall to 72.73% and Precision to 96.00%. By significantly saving edge compute resources while enhancing security recall and detection precision, our system provides an efficient deployment scheme for edge scenarios in smart homes, industrial inspection, energy, and embodied perception.
Introduction
With the rapid advancement of multimodal large models and world models, artificial intelligence is transitioning from the digital to the physical world. Continuous multimodal data streams generated in physical environments hold significant industrial value, provided models can accurately interpret physical signals and make real-time decisions. However, processing these massive, uninterrupted data streams imposes severe performance bottlenecks on physical AI systems.
Consider a typical smart home or industrial inspection scenario: an HD camera continuously records the environment 24 hours a day. Most of the footage consists of normal, repetitive background activity: family members walking, pets sleeping in the corner, or factory assembly lines running routinely. However, the critical events requiring an alert, a state change, or human intervention typically last only a few fleeting seconds:
- In a living room, an elderly person playing with a pet suddenly loses balance, falls heavily onto the floor, and remains motionless.
- Late at night at a substation gate, a suspicious figure briefly appears, triggers a sensor light, and hastily retreats.
For these high-value, diverse physical events, Vision-Language Models (VLMs) demonstrate unprecedented semantic understanding and human-interaction capabilities. VLMs can reason about questions close to human cognition: "What dangerous event is happening in this frame?", "The cat jumping onto the sofa is fine, but alert me if it enters the kitchen."
However, continuously feeding raw 24/7 video streams directly into on-device VLMs causes immediate system bottlenecks in deployment:
- Compute and Power Constraints: On-device hardware has limited resources; continuously running large-parameter VLMs rapidly drains local compute capacity and spikes power consumption.
- Token Explosion: Processing long videos requires injecting high-density video frame tokens. This easily exceeds the context window limits of on-device VLMs and causes compute requirements to scale quadratically.
- Temporal Perception Limits: Most edge VLMs excel at spatial static semantics of single frames but are insensitive to fine-grained changes in object motion, leading to high false-negative rates.
This creates a fundamental contradiction: VLMs possess a high ceiling for visual semantic understanding, but using them directly as continuous scanners is both computationally and economically unviable.
1. From Vision Perception Models to VLMs
Although multimodal Vision-Language Models (VLMs) have significantly elevated the upper bound of visual semantic understanding, vision perception encoders (Vision Encoders) represented by CLIP[1] and SigLIP[2] remain irreplaceable cornerstones in Physical AIOS design, and continue to evolve.
Built on lightweight neural networks (e.g., ViT, CNN), Vision Encoders exhibit low latency and controlled power consumption, making them ideal as always-on edge perception layers. On top of the temporal representations extracted by these encoders, the system can deploy a lightweight event classifier to monitor anomalous motion continuously. In Physical AIOS, the perception model no longer serves as the final semantic adjudicator; instead, it is responsible for "candidate discovery," "temporal window localization," and "physical motion evidence extraction." This compresses the input into high-value slices for the downstream VLM.
Once the perception layer detects a potential high-risk event and wakes the VLM, the VLM serves as the semantic reasoning layer, providing three primary capabilities:
- Open-World Scene Understanding: Eliminates the limitations of traditional classifiers restricted to predefined classes, enabling direct comprehension of arbitrary physical environments and complex natural language instructions.
- Structured Reasoning: Outputs the visual evidence supporting its judgment along with uncertainty scores, preventing false alarms driven by hallucinations.
- Natural Language Interaction: Converts user feedback (e.g., "The dog is just playing, not an anomaly") directly into natural language prompts, decision rules, or local hard cases to drive the data flywheel.
By separating the system boundaries into "perception-layer screening" and "reasoning-layer validation," the system approximates cloud-level semantic understanding within edge resource budgets. Below, we review the characteristics and evolution of these models.
2. Core Models and Technical Evolution
2.1 Vision Encoders
The first step in on-device vision perception is compressing raw pixels into expressive semantic representations. The table below summarizes the technical evolution of five generations of representative vision encoders in terms of architecture and representation:
| Model / Lineage | Core Loss Function | Vision-Text Alignment | Teacher Network Update (EMA) | Aspect Ratio / Resolution Support | Key Advantages & Role |
|---|---|---|---|---|---|
| CLIP (2021) | Global Softmax Loss | Dual-tower end-to-end joint contrastive learning | None | Fixed square crop only | Provides a foundational global contrastive semantic space for coarse open-vocabulary screening. |
| SigLIP (2023) | Pairwise Sigmoid Loss | Binary classification alignment (decoupled batch/compute) | None | Fixed square size only | Eliminates the All-Gather communication bottleneck, offering robust representation for small-batch edge alignment. |
| SigLIP 2 (2025.02) | Sigmoid + LocCa (Localization-Captioning) + Self-supervised | Joint end-to-end optimization with generative auxiliary | Full weight EMA (smooths all encoder weights) | NaFlex variant supporting native aspect ratios and dynamic sequence lengths | Significantly enhances fine-grained object localization and dense features, making it the preferred perception backbone for edge VLMs. |
| TIPSv2 (2026.04) | Sigmoid + LocCa + iBOT++ (Patch-level supervised loss) | Enhanced dense local patch-text alignment | Head-only EMA (EMA updates computed only on the projection head) | Native aspect ratio and dynamic sizes (NaFlex) | Strongly preserves local patch features during pre-training, yielding multiple-fold improvements in zero-shot semantic segmentation and dense visual evidence alignment. |
| DINOv3 (2025.08) | DINO + iBOT + Gram Anchoring (similarity topology anchoring) | Post-hoc text projection | Full weight EMA + early Gram teacher | RoPE + Box jittering, supporting hybrid resolutions | The peak of self-supervised vision. Constrains the geometric space of local features via Gram Anchoring, providing stable, text-unbiased dense depth and spatial topology. |
| InternVideo-Next (2025) | Encoder-Predictor-Decoder decoupled temporal self-supervision | Video-text multimodal contrastive alignment | Full video encoder weight updates | Variable-length and multi-scale temporal sliding windows | Perception base for temporal world models. Specifically captures motion trajectories, velocity, causality, and physical state transitions to generate Top-k anomaly windows. |
CLIP[1:1], introduced by OpenAI, utilizes large-scale image-text contrastive learning to map images and text into a shared semantic space, enabling text concepts like "dog," "person falling," or "loitering at the door" to serve as targets for zero-shot classification. SigLIP[2:1] modifies the contrastive learning loss into a pairwise sigmoid loss, reducing dependence on large batch sizes and cross-device communication. SigLIP 2[3] integrates captioning, self-distillation, masked prediction, and native aspect ratio support into a unified encoder, boosting localization, dense features, and multilingual capabilities.
Meta's DINOv3[4] represents a self-supervised path. Instead of text alignment, it relies on Masked Image Modeling within a Teacher-Student architecture. Building on this, DINOv3 introduces a Gram Anchoring mechanism during long-horizon training to constrain patch-level dense features. This aligns the Gram matrix of the current feature map (representing the second-order self-correlation topology of local patches) with that of the teacher network from an earlier high-density feature phase, locking in local spatial structures and geometric relationships.
DeepMind's TIPSv2[5] focuses on patch-text alignment. While standard alignment handles global concepts ("a dog in the image"), physical AI requires tracking local actions ("child near the stairs," "hand touching a hot surface," "package removed"). TIPSv2 leverages iBOT++ and multi-granularity caption sampling to align patches with text concepts, allowing local visual evidence to enter the language reasoning pipeline.
Videos are more than sequences of images. Physical events are encoded in velocities, sequences, trajectories, contacts, sustained stillness, and state transitions. InternVideo-Next[6] serves not just as a video classifier, but positions the predictor inside a latent world model. Using an Encoder-Predictor-Decoder framework, it learns temporal world representations. In our setup, it handles sliding-window video embedding, candidate event recall, motion evidence extraction, and risk routing. Our experiments leverage the InternVideo-Next encoder.
2.2 Multimodal Vision-Language Models (VLMs)
Cloud-based closed-source VLMs (such as Gemini 3.5[7] and GPT-5.5[8]) provide advanced intelligence. However, in edge multimodal scenarios, they suffer from high API costs, network latency, bandwidth overhead from continuous video transmission, and privacy concerns. In practice, edge and cloud VLMs can cooperate: the edge VLM handles most queries locally at low cost and latency, while hard cases are routed to the cloud for verification and model optimization.
Edge multimodal models are represented by Qwen3.5-VL[9], Gemma 4[10], and MiniCPM-V-4.6[11]. MiniCPM-V-4.6, in particular, offers exceptional performance at low parameter counts (combining Qwen3.5-0.8B[9:1] and SigLIP2-400M[3:1] in co-tuning). It supports 4-bit INT quantization, runs easily on edge NPUs or GPUs with
2.3 Physical World Models (Cosmos 3)
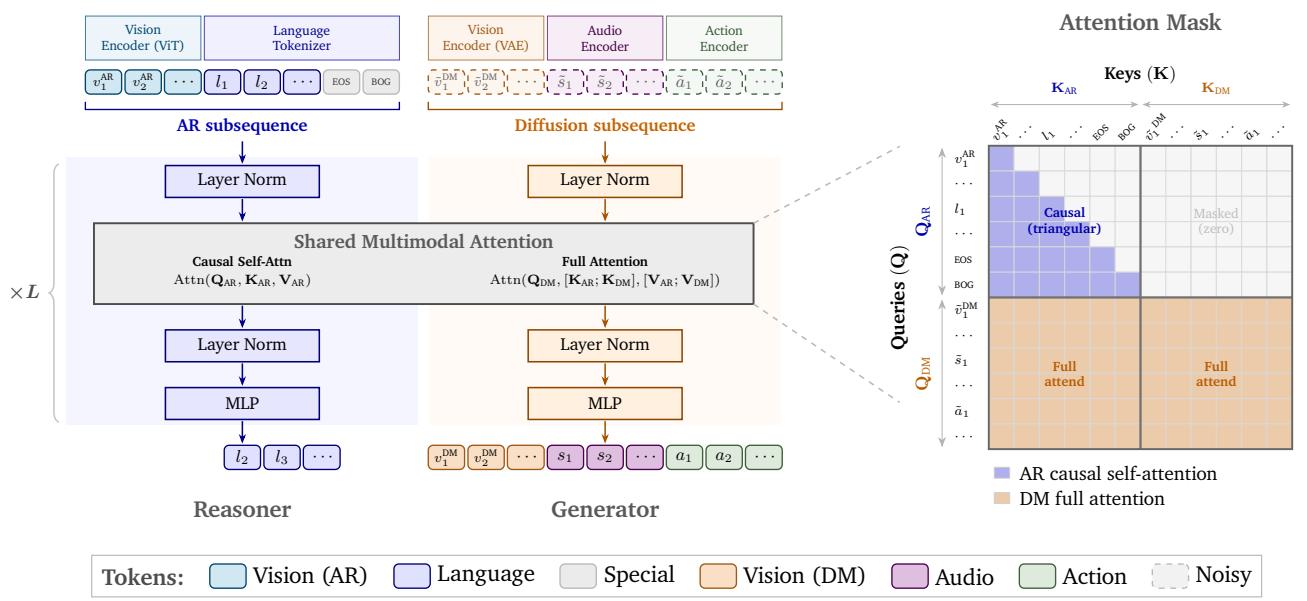
In physical AI, world models are progressing rapidly. NVIDIA's Cosmos 3[13] integrates language understanding, video generation, temporal prediction, and action planning into a unified multimodal architecture:
- Dual-Encoding Mechanism: Employs both a ViT understanding encoder (for high-level semantics and cognitive reasoning) and a video VAE generative encoder (to preserve physical details for video generation).
- MoT (Mixture of Tokens) / Reasoner / Generator: By training on large-scale physical simulation and real-world video datasets via self-supervised prediction, Cosmos 3 can predict future physical dynamics through generative "rollouts" and plan robot actions accordingly.
However, deploying a full Cosmos 3-scale world model at the edge remains computationally prohibitive and does not address the edge-specific constraints targeted here. Our system does not replicate Cosmos 3; instead, we focus on the edge visual perception subsystem, exploring how to combine video encoders and edge VLMs into an efficient, adaptive, and easy-to-tune visual pipeline.
3. Efficient and Reliable Hierarchical Vision System
To achieve real-time semantic understanding within edge power and memory budgets, we designed a hierarchical vision perception and reasoning cascade system (as shown in Figure 3.1). The system runs an always-on, low-power perception pipeline at the bottom layer, paired with an on-demand, high-intelligence cognitive reasoning verifier at the top layer. This architecture reduces compute load on the edge VLM, improves system accuracy, and supports local adaptation via an autonomous data flywheel.
The system consists of four cooperating modules:
- Frontend Perception Layer: An always-on, low-power screening pipeline. The InternVideo-Next Encoder extracts long-range temporal features from the video stream. The Event Classifier models motion energy and physical anomalies using a lightweight decision boundary. The Risk Router evaluates wake-up policies to detect high-risk or anomalous physical actions, filtering out background video streams at low power (filtering 76.5% of normal videos in our test set) and sending a wake-up signal to the cognitive layer.
- Backend Cognitive Reasoning Layer: Composed of the MiniCPM-V VLM, which is activated on-demand upon receiving a wake-up signal. It verifies the semantics of the candidate video slice, structures the logical evidence chain, and outputs a high-confidence JSON decision.
- Policy Decision & Action Execution Layer: The Policy Layer fuses business logic, safety parameters, and geofencing rules to determine alerts or intervention actions. The Actuator executes alerts and routes high-value hard cases (such as false alarms or low-confidence predictions) to the local feedback cache.
- Feedback Adaptation Loop: An optimization engine that utilizes cached hard cases to fine-tune the frontend video encoder offline and update VLM LoRA weights, enabling co-evolution of both layers.
4. Smart Home Experimental Verification: Co-evolution Data Flywheel
To verify the feasibility of the hierarchical cascade system in reducing inference costs and raising the accuracy ceiling, we conducted experiments on the continuous video stream subset of the smarthome-bench[14] smart home security dataset.
We used a dataset containing 1,017 real-world smart home videos. The training set consists of 869 video samples (
All training and evaluation steps (including frontend video encoder LoRA fine-tuning and downstream VLM co-tuning) were executed on an NVIDIA RTX PRO 6000 Blackwell GPU (96GB) compute platform.
4.1 Experimental Results
To evaluate the system's optimization, we compared five progressive configurations:
- S1: VLM Baseline: Direct scanning of all video frames using the edge MiniCPM-V-4.6 VLM (Phase 1).
- S2: Cascade Decision: Introducing an unfrozen InternVideo-Next as a gating screen; the VLM is woken up on-demand (Phase 2).
- S3: Encoder Adaptation: LoRA fine-tuning the frontend video encoder to suppress false activations from daily background motion (Phase 3).
- S4: Feature Fusion: Co-tuning the VLM with an Event-Token projection layer to directly read temporal features (Phase 4 - Branch A).
- S5: Co-evolution: SFT alignment on both the adapted frontend encoder features and the downstream VLM (Phase 4 - Branch B).

The performance metrics on the test set (50 videos: 33 safety anomalies and 17 normal background videos) are summarized in the table below:
| Scheme | Design | Precision | Recall | F1-Score | VLM Wake-up Rate |
|---|---|---|---|---|---|
| S1: VLM Baseline | Edge MiniCPM-V scanning all frames, without frontend perception. | 95.45% | 63.64% | 76.36% | 100.0% |
| S2: Cascade Decision | Unfrozen InternVideo-Next + lightweight SVM gating; on-demand VLM wake-up. | 88.89% | 72.73% | 80.00% | 48.0% |
| S3: Encoder Adaptation | LoRA-tuned video encoder top layers to suppress background wake-ups; downstream VLM unmodified. | 87.10% | 81.82% | 84.38% | 72.0% |
| S4: Feature Fusion | Event-Token projection layer injecting raw temporal features into VLM for co-SFT. | 88.46% | 69.70% | 77.97% | 80.0% |
| S5: Co-evolution | SFT alignment on both the adapted frontend encoder and the downstream VLM LoRA weights. | 96.00% | 72.73% | 82.76% | 74.0% |
4.2 Phase Analysis
4.2.1 S1 to S2: From Full Scanning to Gated Screening
In Phase S1, the VLM baseline achieved 95.45% Precision but missed 12 real security risks (including baby strollers rolling away and night intrusions), resulting in a Recall of 63.64%. This is because static VLMs struggle to model fine-grained temporal trajectories and relative displacements. Furthermore, continuously running the VLM incurs unsustainable edge compute overhead.
In Phase S2, we introduced a multi-chunk cascade system utilizing the frozen InternVideo-Next encoder. A lightweight SVM gating classifier models motion energy and anomalies. When the gating score is
4.2.2 S3: Vision Perception LoRA Tuning
In Phase S3 (Encoder Adaptation), we applied LoRA adaptation to the top 8 attention blocks of the video encoder to suppress false wake-ups caused by household background motion (e.g., curtains blowing, pets running).
This enhanced gating sensitivity and raised the Recall to 81.82%. However, because only the upstream encoder was tuned, the downstream VLM remained an unadapted zero-shot model. When feeding the adapted feature space into the unmodified VLM, feature misalignment occurred. This led to a rebound in false alerts (Precision dropped to 87.10%) and pushed the wake-up rate up to 72.0%.
4.2.3 S4: Two-Stage Feature Fusion
In Phase S4 (Feature Fusion), we introduced feature-level Token fusion to address the VLM's temporal blind spots. We designed an Event-Token projection layer (using learnable multimodal placeholder tokens to pad missing features) to inject 8-slot event tokens directly as physical temporal evidence into the VLM.
Although we co-tuned the VLM with raw temporal features and resolved "Prompt-Target" data conflicts, the lack of adaptation in the upstream encoder limited the Recall to 69.70% and resulted in an 80.0% wake-up rate.
4.2.4 S5: Hierarchical Co-evolution
In Phase S5 (Co-evolution), we combined feature fusion with joint fine-tuning of both the upstream encoder and the downstream VLM. Building on the fine-tuned frontend encoder, we co-aligned the VLM's local LoRA weights to eliminate feature misalignment.
This configuration maintained a 74.0% low wake-up rate (intercepting 76.5% of normal videos at the edge, with only 4 normal clips triggering the VLM, saving 26% of overall compute overhead) while raising the anomaly Recall to 72.73% (9.09% higher than the S1 baseline).
Crucially, S5 suppressed false alarms: false alerts under the Alert_or_Review decision policy dropped to 1, raising Precision to 96.00%. Under the strict Alert (direct notification) policy, the system achieved 0 false alarms (100% Precision), resolving the false alert rebound seen in S3.
4.3 Case Studies and Empirical Analysis
To evaluate the system's physical reasoning, we analyze 6 representative test cases showing their decision paths across configurations:
4.3.1 🚨 Case A: Stroller Runaway Risk
- Visuals (
smarthome_0001): On a front porch, a parent leaves a stroller behind while opening the door. The stroller begins to roll backward down the steps and accelerates into the side lawn. - System Behavior: In the S1 baseline, the VLM processed downsampled static frames, failed to establish temporal continuity, and misclassified the runaway as a "normal stroller passing by" (False Negative). In the S5 co-evolved system, the injected Event-Tokens provided continuous displacement vectors. The VLM recognized the runaway trajectory and triggered a
Reviewdecision at Phase 1, preventing a potential accident.
4.3.2 🚨 Case B: Nocturnal Cougar Intrusion
- Visuals (
smarthome_0028): Late at night (infrared mode), a cougar emerges from the shadow on the right, walks onto the porch, and sniffs near the front door. - System Behavior: In S1, the VLM missed the animal due to low-contrast infrared frames and subtle movements. Under the S5 system, the adapted encoder detected the low-contrast nocturnal motion and immediately woke the VLM. Combining the temporal Event-Tokens and body-shape semantics, the VLM issued a high-confidence
pet_anomalyalert (Alert), securing the home boundary.
4.3.3 🚨 Case C: Nighttime Porch Theft Attempt
- Visuals (
smarthome_0082): A suspicious figure crouches and approaches outdoor furniture on a porch at night, but flees when the motion-sensor light turns on. - System Behavior: In S1, the suspect's rapid movement and motion-blur from the sensor light caused the static frames to lose focus, leading to a missed detection. The S5 co-evolved system captured the abrupt motion and U-turn displacement vector (producing a spike in the Event-Token vectors) at the edge perception layer. The VLM verified the context and issued an
Alert, capturing the threat.
4.3.4 🚨 Case D: Indoor Fall
- Visuals (
smarthome_0021): In a living room, a man plays with a large dog, loses his footing, falls backward onto the floor, and remains static for several seconds. - System Behavior: In S1, the VLM lacked physical modeling of gravity and momentum, classifying the pose as "playing with pet on the floor" (False Negative). In S5, the sharp acceleration during the fall triggered a high gating score (0.945) at the perception layer. Waking the VLM with the Event-Tokens allowed it to identify the loss of balance and subsequent immobility, outputting a
Reviewalert for manual check.
4.3.5 💡 Case E: Child Riding Bike Out of Camera Boundary
- Visuals (
smarthome_0162): A young boy rides his bicycle on a driveway without supervision, gradually moving out of the camera's field of view. - System Behavior: This scenario was missed in both S1 and S5 (classified as
normal_home). Because the boy's movement was smooth and continuous, it did not trigger any motion energy spikes or abrupt physical anomalies in the frontend perception layer. This highlights a limitation: the risk arises from "unsupervised child exiting a safe boundary" rather than physical motion anomalies. Addressing this requires integrating spatial rule-based constraints in the policy layer.
5. Applications: Smart Home, Industrial Energy, Embodied AI
This hierarchical perception and data flywheel architecture can be extended beyond smart homes to industrial energy and embodied intelligence.
5.1 Smart Home
Smart homes are ideal environments for edge-closed-loop deployment. For example, Liko.ai (which designs home hardware as "on-device perceive-understand-remember-act systems"[15]) focuses on transforming home video feeds from passive recorders into active, learning hubs. Their use cases span home security, elderly and child care, object search, and highlight recording.
In these applications, video volume is high, but key events are sparse, and user privacy is paramount. The hierarchical system delivers core value here: by keeping video data processing on-device, the low-power perception model continuously monitors the stream, waking the edge VLM only for "suspected high-risk" or "highlight" events. Through the "observe-understand-warn-interact-flowback" local loop, the system learns the home's normal patterns, transitioning from passive recording to active, privacy-preserving assistance.
5.2 Industrial Energy
In industrial production and substation inspection, AI operates under strict safety and reliability standards. Typical risks include worker trespass, missing PPE, localized equipment overheating, vehicle-pedestrian proximity, and power line obstructions.
Under these conditions, network connectivity is often unreliable, and data privacy policies prohibit cloud transmission. The backend Policy Layer can run deterministic safety rule verification (e.g., "if the gantry crane is operating, enforce a 5-meter exclusion zone below"). By binding the VLM's structured semantic evidence with a deterministic safety verification engine, the system functions as an auditable, deterministic edge safety runtime, executing high-precision safety loops even during network disconnects.
5.3 Embodied AI
For mobile robots and robotic manipulators, the ultimate architecture tends toward a unified World-Action Model (WAM) like Cosmos 3 that combines vision, touch, future prediction, and action generation. However, running high-dimensional generative models continuously in multi-card real-time control loops is extremely resource-intensive.
Our approach can serve as an efficient edge visual perception subsystem for embodied AI: when the environment changes abruptly, when path execution is blocked, or when high-value interaction opportunities are detected, the low-power always-on perception module detects the event, extracts temporal features, and prompts the larger WAM to perform deep physical reasoning and motion replanning. As robots scale and algorithms evolve, we expect this combination of low-power perception gating and high-intelligence cognitive reasoning to become a standard component of embodied stacks.
6. Summary
If a large language model operating system (such as Claude Code or Codex) manages text tokens, tool calls, and reasoning steps, then a Physical AI OS manages continuous sensor streams, physical event proposals, high-risk policy execution, and adaptive feedback loops. Given the scale of real-world physical data and the severe power constraints of edge hardware, many challenges remain. The hierarchical optimization presented here enables the co-evolution of Vision Encoders and VLMs, providing an efficient and reliable pathway for physical AI at the edge.
References
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. "Learning Transferable Visual Models From Natural Language Supervision." ICML, 2021. ↩︎ ↩︎
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, et al. "Sigmoid Loss for Language-Image Pre-training." ICCV, 2023. ↩︎ ↩︎
Michael Tschannen, Alexey Gritsenko, Xiao Wang, et al. "SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features." arXiv:2502.05477, 2025. ↩︎ ↩︎
Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, et al. "DINOv3: Self-Supervised Visual Representation Learning at Scale." arXiv:2508.12030, 2025. ↩︎
DeepMind. "TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment." Technical Report, 2026. ↩︎
Chenting Wang, Yuhan Zhu, Yicheng Xu, et al. "InternVideo-Next: Towards World Understanding Video Models." arXiv:2512.01342, 2025. ↩︎
Google Gemini Team. "Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context." Google Technical Report, 2024. See also Google Blog: "Introducing Gemini 3.5". ↩︎
OpenAI. "GPT-5.5 System Card." OpenAI Technical Report, 2026. ↩︎
Qwen Team. "Qwen3-VL Technical Report." arXiv:2511.08234, 2025. ↩︎ ↩︎
Merve Noyan, Pedro Cuenca, Sergio Paniego, et al. "Welcome Gemma 4: Frontier Multimodal Intelligence on Device." Hugging Face Blog, 2026. ↩︎
OpenBMB. "MiniCPM-V-4.6: Technical Report and Multimodal Computational Analysis." OpenBMB Repository, 2026. ↩︎
Kechen Fang, Yihua Qin, Chongyi Wang, et al. "LLaVA-UHD v4: What Makes Efficient Visual Encoding in MLLMs?" DeepMind Technical Report, arXiv:2604.14812, 2026. ↩︎
NVIDIA. "Cosmos 3: Architecture, Compute and Generative World Models." NVIDIA Technical Report, 2026. ↩︎
Xinyi Zhao, Congjing Zhang, Pei Guo, et al. "SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes." CVPR Workshops, 2025. ↩︎
Liko.ai. "Liko.ai: Edge AI Home Security and Smart Home System." 2026. ↩︎