从语料加工到经验飞轮:大模型数据工程的下一站

大模型过去几年的进化,本质上也是一部数据形态的进化史。
2018 年前后的 BERT、GPT-1 和 GPT-2,主要依赖百科、书籍、网页等文本语料,数据工程的核心问题是规模、覆盖、基础清洗和去重。到 GPT-3、InstructGPT 和 ChatGPT 阶段,数据不再只是预训练语料,而开始被组织成指令、答案、偏好、多轮对话和安全对齐样本。随后,多模态模型的发展又把图文对、视频片段、音频文本、网页结构和文档版面纳入训练体系。进入推理模型和 Agent 阶段之后,代码执行日志、搜索轨迹、工具调用记录,也开始成为新的训练资产。
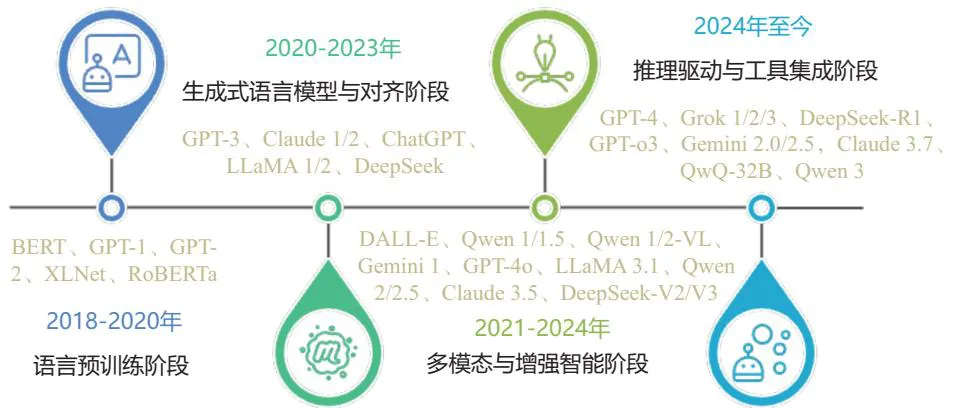
图源:《大模型数据 原理技术与实战》,图 1.1。
随着技术的演进,数据不再只是世界已经留下的文本、图像,而越来越像模型与世界交互后形成的经验沉淀。模型能力的每一次跃迁,背后几乎都伴随着数据来源、数据结构、数据质量和反馈方式的升级。
《大模型数据 原理技术与实战》[1]一书(下文简称《大模型数据》),正是在这一轮数据形态快速演进之后,给出了一个系统化、工程化、可落地的方案:从采集、解析、清洗、标注,到合成、质量评估、反馈治理,再到 PDF 垂类微调和动态数据选择。笔者有幸深度参与了相关产品技术的快速发展和产业落地,这套体系清晰回答了大模型训练调优中最关键的问题:如何把分散、异构、嘈杂的原始材料,转化为可训练、可评估、可治理、可持续迭代的数据资产。
在这套数据工程底座逐渐成熟之后,新的问题开始浮现:当高质量互联网语料逐渐逼近瓶颈,当模型开始进入数学、代码、科学发现、金融预测、软件工程和真实工具操作等任务时,一个更关键的问题随之浮出水面:
如果世界上没有现成答案,模型应该从哪里获得新的训练信号?
这也是本文想讨论的核心判断:大模型数据工程的主战场,正在从 Data Processing 走向动态闭环的 Agentic RL Data Engineering。
过去,模型主要学习人类已经写下来的文本、代码、图像和偏好。现在,模型开始学习自己与工具、验证器和环境交互产生的轨迹。未来,我们不只是更多 tokens,而更需要能够持续产生高质量经验的任务环境、验证反馈和训练闭环。两个技术融合,让模型既能高质量获取现有世界的知识体系,也能够持续试错、验证、发现,并把经验重新压缩为模型能力。
1. 《大模型数据》的工程底座
数据的全生命周期
《大模型数据》把当前数据生命周期分为七个环节:对于大模型的研发应用来说,数据已经不再是简单输入,而是贯穿模型构建全生命周期的核心变量。大模型开发绝大部分的工作,都与数据工程相关;数据直接决定模型能力的上限。
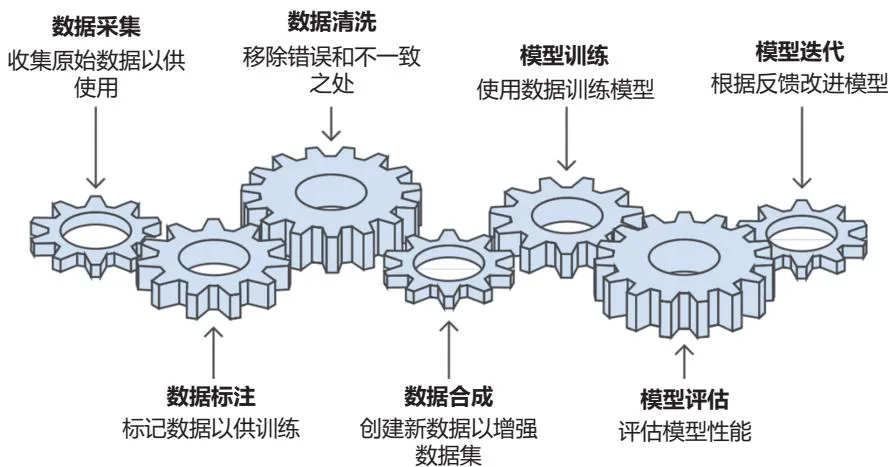
图源:《大模型数据 原理技术与实战》,图 1.4。
这套生命周期框架的意义在于,它把高质量数据这个容易被泛化的概念拆成了可执行的工程问题:语料如何进入模型,PDF、网页、表格、公式和图文混排如何恢复成机器可处理结构,指令数据如何统一格式,偏好数据如何明确比较关系,训练集和评测集如何避免污染,自动生成的数据又如何被评估和治理。
| 阶段 | 核心任务 | 典型方法 | 输出物 |
|---|---|---|---|
| 采集 | 从网页、代码库、专业文档、PDF、多模态资源中获取原始材料 | Common Crawl、爬虫、API、数据库导出 | 原始语料库 |
| 解析 | 把 PDF、网页、表格、公式和图文混排恢复成机器可处理结构 | 布局检测、OCR、公式识别、HTML 解析 | JSON / Markdown 内容块 |
| 清洗 | 去重、去噪、乱码修复、低质过滤和安全过滤 | MinHash、规则过滤、分类器评分 | 高纯净度语料 |
| 标注 | 构造任务监督信号 | 人工标注、半自动标注、LLM-as-Judge | SFT / RLHF 样本 |
| 合成与增强 | 补足覆盖、构造长尾和难例 | Self-Instruct、Evol-Instruct、改写、回译 | 增量训练数据 |
| 质量评估 | 判断数据是否真的可用 | 多维评分、Reward Model、评测矩阵 | 分级数据集 |
| 模型迭代 | 将高质量数据转化为模型能力,并形成动态反馈闭环 | 监督微调(SFT)、RLHF、动态训练 | 领域能力模型 / 迭代新版本 |
PDF 垂类微调是书中非常有代表性的实践案例。很多高价值专业知识天然锁在 PDF 里:论文、教材、行业报告、实验手册、法律文件、金融公告、药品说明书。对人类来说,这些内容是知识;对模型来说,它们往往只是版面复杂、结构破碎、语义关系隐含的非结构化文件。页眉页脚、跨栏排版、表格、公式、图注、参考文献和扫描噪声都会破坏训练样本。
因此,一个典型的 PDF 数据工程流程不是直接把原文扔进模型,而是:
PDF -> 布局解析 -> 内容块 JSON -> 图文/公式/答案对齐
-> 数据合成与增强 -> 多维质量评估 -> LLaMA-Factory / DataFlex 微调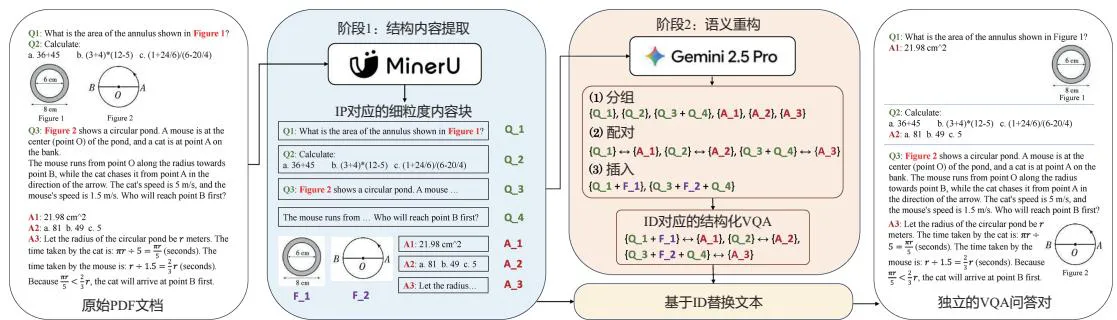
图源:《大模型数据 原理技术与实战》,图 7.1。
在这个过程中,解析器负责把人类阅读版面恢复成结构化内容块;数据治理负责把内容块转成指令、问答、摘要、抽取、推理等监督样本;质量评估判断自动构建的数据是否真的可靠;微调框架负责把这些样本变成领域能力;动态数据选择进一步回答哪些样本更值得训练。这个案例的价值在于,它把“专业知识如何进入模型”拆成了可执行的工程步骤:先通过版面解析恢复结构,再通过语义对齐构造样本,随后用合成与增强补齐分布,最后通过质量评估和微调验证数据是否真正带来模型能力提升。
合成数据与增强
在真实数据不足、标注昂贵、隐私合规受限、长尾场景覆盖不均的局限性下,合成数据愈发成为大模型数据工程中的关键方法,可以扩展分布、补齐难例、统一格式,并在数学、代码、对话、垂类问答和多模态任务中提供冷启动样本。
这类方法大致可以分成几条路线:
| 路线 | 目标 | 典型做法 | 适用场景 |
|---|---|---|---|
| 指令与问答合成 | 构造可直接用于 SFT 的监督样本 | Self-Instruct、种子问题扩写、答案生成、格式约束 | 通用指令、垂类问答、PDF 知识转化 |
| 演化式增强 | 提升任务难度和推理复杂度 | Evol-Instruct、复杂化、约束增加、多步推理链生成 | 数学、代码、复杂推理 |
| 表达与分布增强 | 扩大语言和场景覆盖 | 改写、回译、参数扰动、角色和情境变换 | 多轮对话、小语种、长尾表达 |
| 程序化与仿真合成 | 创造真实世界难以采集的样本 | 数字孪生、物理仿真、传感器模拟、多模态渲染 | 自动驾驶、工业质检、医疗影像、金融风控 |
| 模型在环标注 | 降低人工标注成本 | 预标注、质量打分、一致性校验、拒绝采样 | 大规模数据治理、偏好数据、评测集构建 |
Self-Instruct[2] 通过模型自举生成指令、输入和输出,再过滤无效或相似样本,展示了几乎不依赖人工标注的指令对齐路线。WizardMath[3] 则把 Evol-Instruct 扩展到数学推理,通过强化学习和过程监督提升开放模型的数学能力。在 PDF 垂类微调这样的场景里,合成数据还承担了知识重组的角色:它把解析后的内容块转成问题、答案、摘要、抽取、判断、推理链等训练对象,让原本只适合人阅读的材料变成模型可以学习的监督信号。
因此,合成数据的价值不只是扩量,而是让数据工程从被动采集世界已经给出的样本,走向主动创造模型需要的样本。它是静态语料工程迈向经验工程之前的关键一步:系统开始主动设计任务、控制分布、制造难例,并把数据生产从人工语料为主推进到模型在环流程。
从这个角度看,下文我们阐述的动态闭环的 Agentic Data Engineering 也是对当前技术的自然延展。静态语料、合成数据、质量评估、反馈治理和垂类训练构成了基础的数据底座;在此之上,智能体与环境交互产生的轨迹、验证器反馈、失败修复和任务变体,被可靠的地记录、筛选、增强、回放和重新训练。
2. 从通过验证到学会发现
尽管强合成数据管线已经大量引入类似于强化学习的反馈验证机制:数学可以用答案匹配、过程奖励模型或符号验证器;代码可以在沙盒里执行单元测试。问题在于,即使经过验证,合成数据本质上仍然是静态的、离线的,它通常是一条 ”生成 -> 验证 -> 过滤 -> SFT“ 单向流水线。模型学到的是通过验证的样本,而不是如何在环境中试错、修正和改进。它看到的是事后筛选出的成功答案,却不一定学会了自我去发现成功答案。
这和 RL + 环境交互之间有本质区别:
| 维度 | 合成数据 + SFT | RL + 环境交互 |
|---|---|---|
| trace 生成 | 离线、一次性生成 | 在线、模型与环境动态交互 |
| 分布 | 模型当前分布下的采样 | 实际任务分布中的 on-policy 探索 |
| 反馈 | 生成后静态验证 | 行动后环境即时反馈 |
| 学习方式 | 模仿通过验证的样本 | 从行动后果中更新策略 |
| 角色 | 能力冷启动 | 持续在能力边界探索 |
DeepSeekMath[4] 提供了一个清晰例子:它不是简单把正确答案拿来做 SFT,而是让同一个问题生成多条候选,再通过组内相对奖励估计优势,不断迭代改进模型。这样,模型训练信号从静态答案转向了模型自己采样出的候选分布。
ether0[5] 在化学推理中也呈现出类似结构。它先用长 CoT SFT 冷启动,再在任务族内做 specialist GRPO,收集正确轨迹蒸馏回 generalist,最后进行 generalist GRPO。合成数据只是 bootstrap,真正拉开能力差距的是模型在任务分布中的反复 rollout、验证、筛选和再训练。
因此,合成数据 + 静态验证解决了如何生产高质量静态样本的问题,但它无法替代模型在环境中行动、获得反馈、修正策略的过程。前者是后者的 bootstrap,后者是前者的自然延伸。
3. 走向 Era of Experience
David Silver 和 Richard Sutton 在《Welcome to the Era of Experience》[6] 中提出,一个新的 AI 阶段将由智能体从经验中学习来定义。过去十年的主流 AI 主要依赖人类生成数据:网页、书籍、代码、人工偏好、专家示范。这让 LLM 获得了广泛能力,但也把模型限制在人类已经表达过的知识空间里。而经验时代的关键,不是让模型继续模仿文本,而是让智能体在环境中行动、观察、获得反馈,并用这些经验更新能力。
Silver 并不是简单回到传统 RL。更准确地说,他在把 LLM 先验、搜索规划、验证器反馈和自生成经验重新组合。LLM 提供丰富的先验和表达能力,RL 提供目标驱动的策略改进,环境提供真实反馈,搜索提供扩大探索范围的方法。合在一起,它们构成一种混合路线:先用人类数据得到强基座,再用经验数据突破人类语料的边界。
AlphaProof[7] 是这一思想最清晰的案例之一。它把数学证明转成了可验证的 RL 环境:状态是 Lean 当前 tactic state,动作是模型生成的 Lean tactic,转移由 Lean 执行 tactic 后产生,奖励来自证明完成、失败反馈和搜索路径,策略和值函数则借鉴 AlphaZero[8] 风格的搜索与学习。这里真正重要的不是模型能做奥数题,而是数学被改造成了经验数据工厂:
首先,Lean kernel 提供高可靠验证反馈。一个 tactic 是否合法、证明状态是否推进、最终证明是否完成,都可以由形式系统裁决。验证器把原本模糊的推理质量变成可学习信号。证明过程天然形成高质量轨迹。成功证明不是一个孤立答案,而是一串状态、动作、观察和验证反馈。失败路径也有价值,因为它们告诉模型哪些搜索方向走不通。
其次,自动形式化和问题变体扩大了经验来源。AlphaProof 通过 Gemini 模型把自然语言问题转成 Lean 形式化问题,并利用大量问题变体进行训练和测试时适应。这意味着经验数据并不只来自人工手写证明,而来自模型、形式系统和搜索过程共同构建的环境。
最后,测试时 RL 说明模型在推理阶段也可以围绕特定任务继续学习。对于最难问题,系统可以生成相关变体,从这些变体中获得问题特定经验,再回到原题。这已经不是传统意义上的一次性推理,而是一种面向单个任务的局部学习过程。
这给数据工程带来的深刻的启示:经验不只是训练任务策略的数据,也可能成为改进搜索策略、奖励设计和学习规则的数据。未来的数据团队不只是在准备训练集,还要设计任务环境、验证反馈、搜索空间和经验回放机制。数据团队、RL 团队和 Agent 团队的边界会越来越模糊。
面向未来,高价值、高可靠 AI 的关键不是只靠更大语料预训练,也不是只靠从零 RL,而是在高质量基座模型的基础上,让系统持续试错、验证、发现,并把这些经验重新压缩回模型能力。这在我们前文的 Agentic RL 博客 I & II 也有比较充分的算法和案例阐述。
5. 下一代大模型数据飞轮
如果把前面的讨论总结成一个系统蓝图,下一代大模型数据工程不是相对固化的数据管线,而是模型、数据和环境的联动系统:持续生成任务,让智能体 rollout,用验证器裁决结果,筛选轨迹,再把成功、失败和修正路径回流到训练。
这代表三阶段范式迁移:
| 范式 | 核心问题 | 数据对象 | 关键能力 |
|---|---|---|---|
| Static Data | 如何把已有数据做干净 | 文本、代码、图文对、PDF 样本 | 采集、解析、清洗、标注、评估 |
| Synthetic Data | 如何主动扩展数据 | 指令、问答、变体、推理链 | 生成、改写、增强、筛选 |
| Closed-Loop Agentic Data | 如何让模型从行动和反馈中学习 | 轨迹、验证反馈、失败修复、任务变体 | 环境构造、验证、回放、RL / 蒸馏 |
这三个阶段递进叠加:Static Data 是底座,Synthetic Data 是 bootstrap,Closed-Loop Agentic Data 是持续进化的引擎,并包含以下模块:
第一是 Task Generator。它不断生成任务、变体和难例,让模型停留在能力边界附近。任务太简单,全对没有训练信号;任务太难,全错也没有训练信号。好的任务生成器要根据模型表现自适应调节难度,把失败案例反馈回来,生成更有针对性的下一轮任务。
第二是 Agent Rollout。模型在环境中行动,调用工具、搜索网页、执行代码、尝试证明、提交候选方案或规划实验。Rollout 的目标不是一次性给出答案,而是探索可验证空间。
第三是 Verifier / Reward。环境或验证器把行动结果转化为可学习信号。代码任务里是测试和运行日志;数学任务里是 Lean kernel;化学任务里是 RDKit、分子式约束、性质预测器和数据库;未来预测里是现实 resolution 与过程 rubric;科学工程任务里是 evaluator、仿真器或真实实验结果。
第四是 Trajectory Learning。轨迹按结果动态分流:高分轨迹进入 RL 和蒸馏,失败轨迹进入 hindsight supervision 和错误修复数据,不同任务族按难度形成 curriculum,实现自适应训练调度。
这套系统有望成为下一代智能公司的护城河:高质量人类语料会越来越稀缺,但高质量经验可以由更强的智能体和更好的环境持续生产。静态数据集容易被复制,任务环境、验证器、工具接口、反馈协议和训练闭环更难复制。模型越强,越能探索更难任务;任务越难,越能产生更高价值经验;更高价值经验又反过来训练更强模型。
传统数据飞轮可以写成:
在此基础之上,新一代的数据飞轮进一步包括了如下增强:
这条链条里,数据不再只是被收集、清洗和存储的对象,而是被环境、验证器、智能体和训练系统共同生产出来的过程轨迹。
小结
《大模型数据》一书系统回答了大模型时代“数据如何成为能力”的问题:把采集、解析、清洗、标注、合成、评估、治理和垂类微调组织成一套完整框架,让原始材料能够转化为模型能力。
合成数据让数据工程从被动采集走向主动构造,可以补足长尾、扩大任务覆盖并引入质量反馈;但如果停留在离线生成和静态过滤,也很难让模型解决实际中的专业复杂问题。
而 Era of Experience 和 Agentic RL 进一步把数据生产推向环境、验证器、智能体和训练闭环的协同系统。下一代竞争不只是更多 tokens,而是谁能持续生成任务、沉淀交互经验,并把成功、失败和修正路径回流为新的数据资产。数据工程没有走向终点,而是在升级;《大模型数据》给出了底座,持续闭环学习的 Agentic Data Engineering 指向下一站。
参考文献
何聪辉, 吴郦军, & 张文涛. 大模型数据 原理技术与实战. 电子工业出版社 (2025). ↩︎
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., & Hajishirzi, H. "Self-Instruct: Aligning Language Models with Self-Generated Instructions." ACL (2023). ↩︎
Luo, H., Sun, Q., Xu, C., Zhao, P., Lou, J., Tao, C., et al. "WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct." arXiv preprint arXiv:2308.09583 (2023). ↩︎
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., et al. "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models." arXiv preprint arXiv:2402.03300 (2024). ↩︎
Narayanan, S. M., Braza, J. D., Griffiths, R.-R., Bou, A., Wellawatte, G., Ramos, M. C., et al. "Training a Scientific Reasoning Model for Chemistry." arXiv preprint arXiv:2506.17238 (2025). ↩︎
Silver, D., & Sutton, R. S. "Welcome to the Era of Experience." Google AI / Designing an Intelligence preprint (2025). ↩︎
Hubert, T., Mehta, R., Sartran, L., Horváth, M. Z., Žužić, G., Wieser, E., et al. "Olympiad-level formal mathematical reasoning with reinforcement learning." Nature (2026). ↩︎
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., et al. "A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play." Science (2018). ↩︎