From Data Processing to the Experience Flywheel: The Next Stage for LLM Data Engineering

The evolution of large language models over the past few years is essentially an evolutionary history of data formats.
Around 2018, models like BERT, GPT-1, and GPT-2 relied primarily on text corpora from encyclopedias, books, and web pages. The core problems of data engineering were scale, coverage, basic cleaning, and deduplication. By the stages of GPT-3, InstructGPT, and ChatGPT, data was no longer just pre-training corpora; it began to be organized into instructions, answers, preferences, multi-turn dialogues, and safety alignment samples. Subsequently, the development of multimodal models integrated image-text pairs, video clips, audio transcripts, web structures, and document layouts into the training system. Entering the era of reasoning models and Agents, code execution logs, search trajectories, and tool invocation records have also become new training assets.
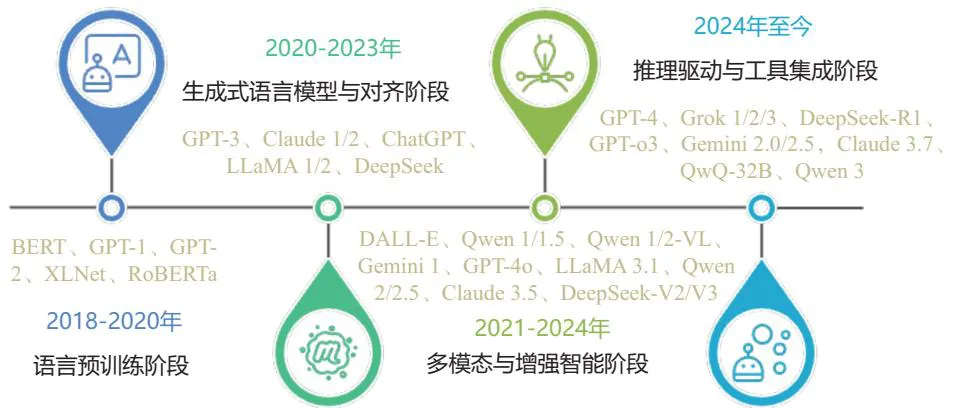
Source: LLM Data: Principles, Technology and Practice, Figure 1.1.
As technology evolves, data is no longer just the text and images already left by the world, but increasingly resembles the accumulated experience formed after the model interacts with the world. Almost every leap in model capability is accompanied by upgrades in data sources, data structures, data quality, and feedback mechanisms.
The book LLM Data: Principles, Technology and Practice[1] (hereafter referred to as "LLM Data"), published right after this rapid evolution of data formats, provides a systematic, engineering-oriented, and implementable solution: from collection, parsing, cleaning, and annotation, to synthesis, quality evaluation, feedback governance, and further to domain-specific PDF fine-tuning and dynamic data selection. Having had the privilege to deeply participate in the rapid development and industrial landing of related products and technologies, I believe this system clearly answers the most critical question in LLM training and fine-tuning: how to transform scattered, heterogeneous, and noisy raw materials into trainable, evaluable, governable, and continuously iterable data assets.
As this foundation of data engineering matures, new questions begin to emerge: when high-quality Internet corpora gradually approach their limits, and when models begin to tackle tasks like mathematics, coding, scientific discovery, financial forecasting, software engineering, and real-world tool manipulation, a more critical question surfaces:
If there are no ready-made answers in the world, where should models obtain new training signals?
This is also the core judgment discussed in this article: the main battlefield of LLM data engineering is shifting from static Data Processing to dynamic, closed-loop Agentic RL Data Engineering.
In the past, models mainly learned from text, code, images, and preferences already written down by humans. Now, models begin to learn from the trajectories generated by their own interactions with tools, verifiers, and environments. In the future, we will not merely need more tokens, but task environments, verification feedback, and training closed-loops capable of continuously producing high-quality experiences. The fusion of the two allows the model not only to acquire the existing knowledge system of the world with high quality but also to continuously trial-and-error, verify, discover, and compress these experiences back into model capabilities.
1. The Foundation of LLM Data Engineering
The Full Life Cycle of Data
"LLM Data" divides the current data life cycle into seven stages. For the R&D and application of LLMs, data is no longer a simple input but a core variable running through the entire life cycle of model construction. The vast majority of work in large model development is related to data engineering; data directly determines the upper limit of model capabilities.
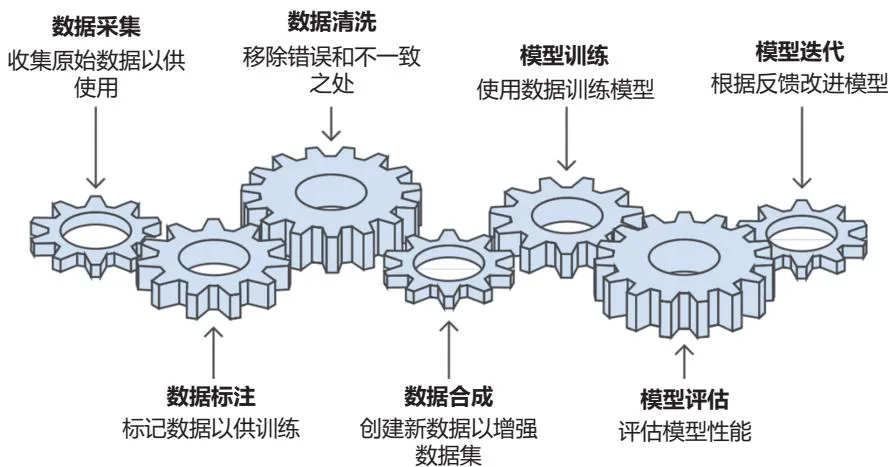
Source: LLM Data: Principles, Technology and Practice, Figure 1.4.
The significance of this life cycle framework is that it breaks down the easily generalized concept of "high-quality data" into actionable engineering problems: how corpora enter the model; how PDFs, web pages, tables, formulas, and mixed graphics-text are restored into machine-processable structures; how instruction data is unified in format; how preference data defines clear comparison relations; how training and evaluation sets avoid contamination; and how automatically generated data is evaluated and governed.
| Stage | Core Task | Typical Methods | Outputs |
|---|---|---|---|
| Collection | Acquiring raw materials from web pages, code repositories, professional documents, PDFs, and multimodal resources | Common Crawl, spiders, APIs, database exports | Raw corpora |
| Parsing | Restoring PDFs, web pages, tables, formulas, and mixed layouts into machine-processable structures | Layout detection, OCR, formula recognition, HTML parsing | JSON / Markdown content blocks |
| Cleaning | Deduplication, denoising, gibberish repair, low-quality filtering, and safety filtering | MinHash, rule-based filtering, classifier scoring | High-purity corpora |
| Annotation | Constructing task supervision signals | Manual annotation, semi-automatic annotation, LLM-as-Judge | SFT / RLHF samples |
| Synthesis & Augmentation | Filling coverage gaps, constructing long-tail and hard examples | Self-Instruct, Evol-Instruct, rewriting, back-translation | Incremental training data |
| Quality Evaluation | Judging whether the data is truly usable | Multi-dimensional scoring, Reward Models, evaluation matrices | Graded datasets |
| Model Iteration | Transforming high-quality data into model capabilities and forming a dynamic feedback loop | Supervised Fine-Tuning (SFT), RLHF, dynamic training | Domain-specific models / New iterations |
Domain-specific PDF fine-tuning is a highly representative practical case in the book. A lot of high-value professional knowledge is naturally locked in PDFs: papers, textbooks, industry reports, lab manuals, legal documents, financial announcements, and drug instructions. For humans, these contents are knowledge; for models, they are often just unstructured files with complex layouts, broken structures, and implicit semantic relations. Headers, footers, multi-column layouts, tables, formulas, captions, references, and scanning noise can all corrupt training samples.
Therefore, a typical PDF data engineering pipeline is not to throw the original text directly into the model, but rather:
PDF -> Layout Parsing -> Content Block JSON -> Image-Text/Formula/QA Alignment
-> Data Synthesis & Augmentation -> Multi-dimensional Quality Evaluation -> LLaMA-Factory / DataFlex Fine-tuning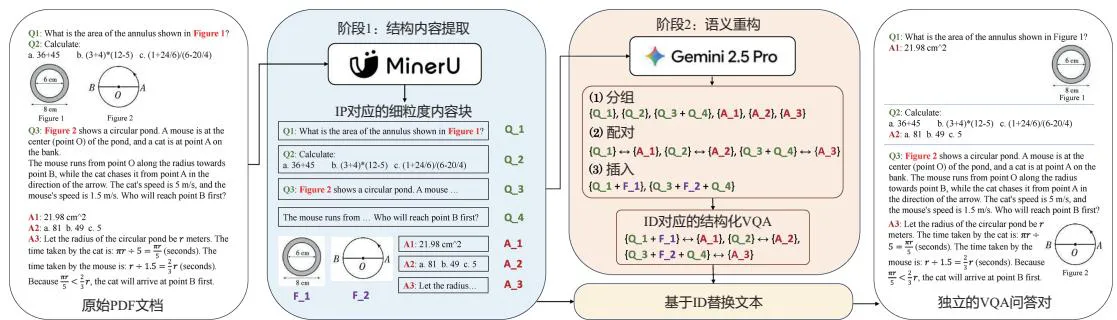
Source: LLM Data: Principles, Technology and Practice, Figure 7.1.
In this process, the parser is responsible for restoring human-readable layouts into structured content blocks; data governance is responsible for converting content blocks into supervision samples such as instructions, QA pairs, summaries, extractions, and reasoning paths; quality evaluation judges whether the automatically constructed data is truly reliable; the fine-tuning framework converts these samples into domain capabilities; and dynamic data selection further answers which samples are more worth training on. The value of this case lies in its breakdown of "how professional knowledge enters the model" into actionable engineering steps: first restoring structure through layout parsing, then constructing samples through semantic alignment, subsequently filling distribution gaps with synthesis and augmentation, and finally verifying whether the data truly brings about an enhancement in model capability through quality evaluation and fine-tuning.
Synthetic Data and Augmentation
Given the limitations of insufficient real data, expensive annotation, privacy and compliance constraints, and uneven coverage of long-tail scenarios, synthetic data has increasingly become a key method in LLM data engineering. It can expand distributions, fill in hard examples, unify formats, and provide cold-start samples for math, coding, dialogue, domain-specific QA, and multimodal tasks.
These methods can be roughly divided into several routes:
| Route | Goal | Typical Practices | Applicable Scenarios |
|---|---|---|---|
| Instruction & QA Synthesis | Constructing supervision samples directly usable for SFT | Self-Instruct, seed question expansion, answer generation, format constraints | General instructions, domain QA, PDF knowledge conversion |
| Evolutionary Augmentation | Increasing task difficulty and reasoning complexity | Evol-Instruct, complexification, adding constraints, multi-step reasoning chain generation | Math, coding, complex reasoning |
| Expression & Distribution Augmentation | Expanding language and scenario coverage | Rewriting, back-translation, parameter perturbation, role and context switching | Multi-turn dialogues, low-resource languages, long-tail expressions |
| Programmatic & Simulation Synthesis | Creating samples difficult to collect in the real world | Digital twins, physics simulations, sensor mockups, multimodal rendering | Autonomous driving, industrial inspection, medical imaging, financial risk control |
| Model-in-the-Loop Annotation | Reducing manual annotation costs | Pre-annotation, quality scoring, consistency checking, rejection sampling | Large-scale data governance, preference data, evaluation set construction |
Self-Instruct[2] demonstrated a virtually annotation-free instruction alignment route by having the model bootstrap instructions, inputs, and outputs, and then filtering invalid or similar samples. WizardMath[3] extended Evol-Instruct to mathematical reasoning, enhancing the math capabilities of open models through reinforcement learning and process supervision. In scenarios like PDF domain fine-tuning, synthetic data also assumes the role of knowledge reorganization: it converts parsed content blocks into training targets like questions, answers, summaries, extractions, judgments, and reasoning chains, transforming materials originally meant only for human reading into supervision signals the model can learn from.
Therefore, the value of synthetic data is not just in increasing volume, but in shifting data engineering from passively collecting samples the world has already provided, to actively creating samples the model needs. It is the crucial step before static corpus engineering transitions to experience engineering: the system begins to actively design tasks, control distributions, create hard examples, and advance data production from a manual-corpus-centric approach to a model-in-the-loop process.
From this perspective, the dynamic, closed-loop Agentic Data Engineering discussed below is a natural extension of current technologies. Static corpora, synthetic data, quality evaluation, feedback governance, and domain training constitute the foundational data infrastructure; on top of this, trajectories, verifier feedback, failure repairs, and task variants generated by agent-environment interactions are reliably recorded, filtered, augmented, replayed, and retrained.
2. From Static Verification to Learning to Discover
Although strong synthetic data pipelines have widely introduced feedback verification mechanisms akin to reinforcement learning—math can use answer matching, Process Reward Models (PRMs), or symbolic verifiers; code can execute unit tests in a sandbox—the problem remains that even after verification, synthetic data is inherently static and offline. It is usually a one-way pipeline of "Generation -> Verification -> Filtering -> SFT". What the model learns are the samples that passed verification, rather than how to trial-and-error, correct, and improve in an environment. It sees the successful answers filtered out after the fact, but may not necessarily learn the process of discovering successful answers itself.
This constitutes a fundamental difference between it and RL + Environmental Interaction:
| Dimension | Synthetic Data + SFT | RL + Environmental Interaction |
|---|---|---|
| Trace Generation | Offline, one-time generation | Online, dynamic interaction between model and environment |
| Distribution | Sampling under the model's current distribution | On-policy exploration within the actual task distribution |
| Feedback | Static verification after generation | Immediate environmental feedback after taking action |
| Learning Method | Imitating samples that passed verification | Updating policy from the consequences of actions |
| Role | Capability cold-start | Continuous exploration at the boundary of capabilities |
DeepSeekMath[4] provides a clear example: instead of simply taking the correct answer for SFT, it generates multiple candidates for the same question, estimates advantages through intra-group relative rewards, and continuously iteratively improves the model. In this way, the model's training signal shifts from static answers to the candidate distribution sampled by the model itself.
ether0[5] exhibits a similar structure in chemistry reasoning. It first uses long-CoT SFT for cold-starting, then performs specialist GRPO within task families, collects correct trajectories to distill back into a generalist model, and finally conducts generalist GRPO. Synthetic data is merely a bootstrap; what truly widens the capability gap is the model's repeated rollout, verification, filtering, and retraining within the task distribution.
Therefore, "synthetic data + static verification" solves the problem of how to produce high-quality static samples, but it cannot replace the process of the model acting in the environment, obtaining feedback, and correcting its policy. The former is the bootstrap for the latter, and the latter is the natural extension of the former.
3. Towards the Era of Experience
David Silver and Richard Sutton proposed in "Welcome to the Era of Experience"[6] that a new phase of AI will be defined by agents learning from experience. Over the past decade, mainstream AI has relied primarily on human-generated data: web pages, books, code, manual preferences, and expert demonstrations. This has endowed LLMs with broad capabilities, but also confined models within the knowledge space already expressed by humans. The key to the Era of Experience is not to have the model continue imitating text, but to let the agent act, observe, obtain feedback in the environment, and use these experiences to update its capabilities.
Silver is not simply returning to traditional RL. More accurately, he is recombining LLM priors, search planning, verifier feedback, and self-generated experience. LLMs provide rich priors and expression capabilities, RL provides goal-driven policy improvements, the environment provides real-world feedback, and search provides methods to expand the scope of exploration. Together, they form a hybrid route: first obtaining a strong base model using human data, and then breaking through the boundaries of human corpora using experience data.
AlphaProof[7] is one of the clearest examples of this idea. It turns mathematical theorem proving into a verifiable RL environment: the state is the current Lean tactic state, the action is a Lean tactic generated by the model, the transition is produced by Lean executing the tactic, and the reward comes from proof completion, failure feedback, and search paths. The policy and value functions draw inspiration from AlphaZero-style[8] search and learning. What's truly important here is not that the model can solve Math Olympiad problems, but that mathematics has been transformed into an experience data factory:
First, the Lean kernel provides highly reliable verification feedback. Whether a tactic is valid, whether the proof state has advanced, and whether the final proof is completed can all be adjudicated by the formal system. The verifier transforms originally ambiguous reasoning quality into learnable signals. The proof process naturally forms high-quality trajectories. A successful proof is not an isolated answer, but a sequence of states, actions, observations, and verification feedback. Failed paths are also valuable because they tell the model which search directions are unviable.
Second, autoformalization and problem variants expand the sources of experience. AlphaProof translates natural language problems into Lean formal problems via the Gemini model, and utilizes a large number of problem variants for training and test-time adaptation. This means that experience data no longer comes solely from manually written proofs, but from environments co-constructed by the model, formal systems, and search processes.
Finally, test-time RL illustrates that models can also continue to learn around specific tasks during the inference phase. For the hardest problems, the system can generate related variants, gain problem-specific experience from these variants, and then return to the original problem. This is no longer one-shot inference in the traditional sense, but a localized learning process oriented towards a single task.
The implications for data engineering are profound: experience is not just data for training task policies, but could also become data for improving search strategies, reward designs, and learning rules. Future data teams will not just prepare training sets, but will design task environments, verification feedback, search spaces, and experience replay mechanisms. The boundaries between data teams, RL teams, and Agent teams will become increasingly blurred.
Looking towards the future, the key to high-value, highly reliable AI is not solely relying on larger pre-training corpora, nor solely relying on RL from scratch. Instead, it is about building on high-quality base models, allowing systems to continuously trial-and-error, verify, discover, and compressing these experiences back into model capabilities. This is also relatively fully elaborated with algorithms and cases in our previous Agentic RL blog posts I & II.
5. The Next-Generation LLM Data Flywheel
Summarizing the preceding discussions into a systemic blueprint, next-generation LLM data engineering is not a relatively fixed data pipeline, but a coupled system of models, data, and environments: continuously generating tasks, letting agents rollout, adjudicating results with verifiers, filtering trajectories, and then recycling successes, failures, and correction paths back into training.
This represents a three-stage paradigm shift:
| Paradigm | Core Problem | Data Objects | Key Capabilities |
|---|---|---|---|
| Static Data | How to clean existing data | Text, code, image-text pairs, PDF samples | Collection, parsing, cleaning, annotation, evaluation |
| Synthetic Data | How to proactively expand data | Instructions, QA, variants, reasoning chains | Generation, rewriting, augmentation, filtering |
| Closed-Loop Agentic Data | How to make models learn from actions and feedback | Trajectories, verification feedback, failure repairs, task variants | Environment construction, verification, replay, RL / Distillation |
These three stages are not mutually exclusive but progressively cumulative. Static Data is the foundation, Synthetic Data is the bootstrap, and Closed-Loop Agentic Data is the engine for continuous evolution, comprising the following modules:
First is the Task Generator. It continuously generates tasks, variants, and hard examples to keep the model near its capability boundary. If tasks are too easy, getting everything right provides no training signal; if tasks are too hard, getting everything wrong also provides no training signal. A good task generator must adaptively adjust difficulty based on model performance, feed back failure cases, and generate more targeted tasks for the next round.
Second is Agent Rollout. The model acts in the environment, invoking tools, searching web pages, executing code, attempting proofs, proposing candidates, or planning experiments. The goal of rollout is not to provide a one-shot answer, but to explore the verifiable space.
Third is Verifier / Reward. The environment or verifier transforms the action results into learnable signals. In coding tasks, these are tests and execution logs; in math tasks, it's the Lean kernel; in chemistry tasks, it's RDKit, molecular constraints, property predictors, and databases; in future forecasting, it's real-world resolution and process rubrics; in scientific engineering tasks, it's evaluators, simulators, or actual experimental results.
Fourth is Trajectory Learning. Trajectories are dynamically shunted based on results: high-scoring trajectories enter RL and distillation, while failed trajectories enter hindsight supervision and error-repair data. Different task families form a curriculum based on difficulty, enabling adaptive training scheduling.
This system is poised to become the moat for next-generation vertical AI companies: high-quality human corpora will become increasingly scarce, but high-quality experiences can be continuously produced by stronger agents and better environments. Static datasets are easy to copy, whereas task environments, verifiers, tool interfaces, feedback protocols, and training closed-loops are much harder to replicate. The stronger the model, the better it can explore harder tasks; the harder the tasks, the more high-value experiences they yield; and higher-value experiences, in turn, train even stronger models.
A traditional data flywheel can be depicted as:
Building on this, the next-generation data flywheel incorporates the following enhancements:
In this chain, data is no longer just an object to be collected, cleaned, and stored, but a process trajectory jointly produced by the environment, verifiers, agents, and the training system.
Summary
The book "LLM Data" systematically answers the question of "how data becomes capability" in the era of large models: organizing collection, parsing, cleaning, annotation, synthesis, evaluation, governance, and domain fine-tuning into a complete framework, enabling raw materials to be transformed into model capabilities.
Synthetic data moves data engineering from passive collection to active construction, filling long tails, expanding task coverage, and introducing quality feedback; but if it remains stuck in offline generation and static filtering, it's also difficult to empower models to solve complex professional problems in reality.
The Era of Experience and Agentic RL further push data production into a collaborative system of environments, verifiers, agents, and training closed-loops. The next-generation competition is not just about more tokens, but about who can continuously generate tasks, accumulate interaction experiences, and recycle success, failure, and correction paths into new data assets. Data engineering has not reached its end; it is upgrading. "LLM Data" provides the foundation, and the continuously closed-loop learning of Agentic Data Engineering points to The Next Stage.
References
He, C., Wu, L., & Zhang, W. LLM Data: Principles, Technology and Practice. Publishing House of Electronics Industry (2025). ↩︎
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., & Hajishirzi, H. "Self-Instruct: Aligning Language Models with Self-Generated Instructions." ACL (2023). ↩︎
Luo, H., Sun, Q., Xu, C., Zhao, P., Lou, J., Tao, C., et al. "WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct." arXiv preprint arXiv:2308.09583 (2023). ↩︎
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., et al. "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models." arXiv preprint arXiv:2402.03300 (2024). ↩︎
Narayanan, S. M., Braza, J. D., Griffiths, R.-R., Bou, A., Wellawatte, G., Ramos, M. C., et al. "Training a Scientific Reasoning Model for Chemistry." arXiv preprint arXiv:2506.17238 (2025). ↩︎
Silver, D., & Sutton, R. S. "Welcome to the Era of Experience." Google AI / Designing an Intelligence preprint (2025). ↩︎
Hubert, T., Mehta, R., Sartran, L., Horváth, M. Z., Žužić, G., Wieser, E., et al. "Olympiad-level formal mathematical reasoning with reinforcement learning." Nature (2026). ↩︎
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., Guez, A., et al. "A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play." Science (2018). ↩︎