Agentic RL (Part III):
Verl、SkyRL 架构分析到 Retool-RL 案例实践
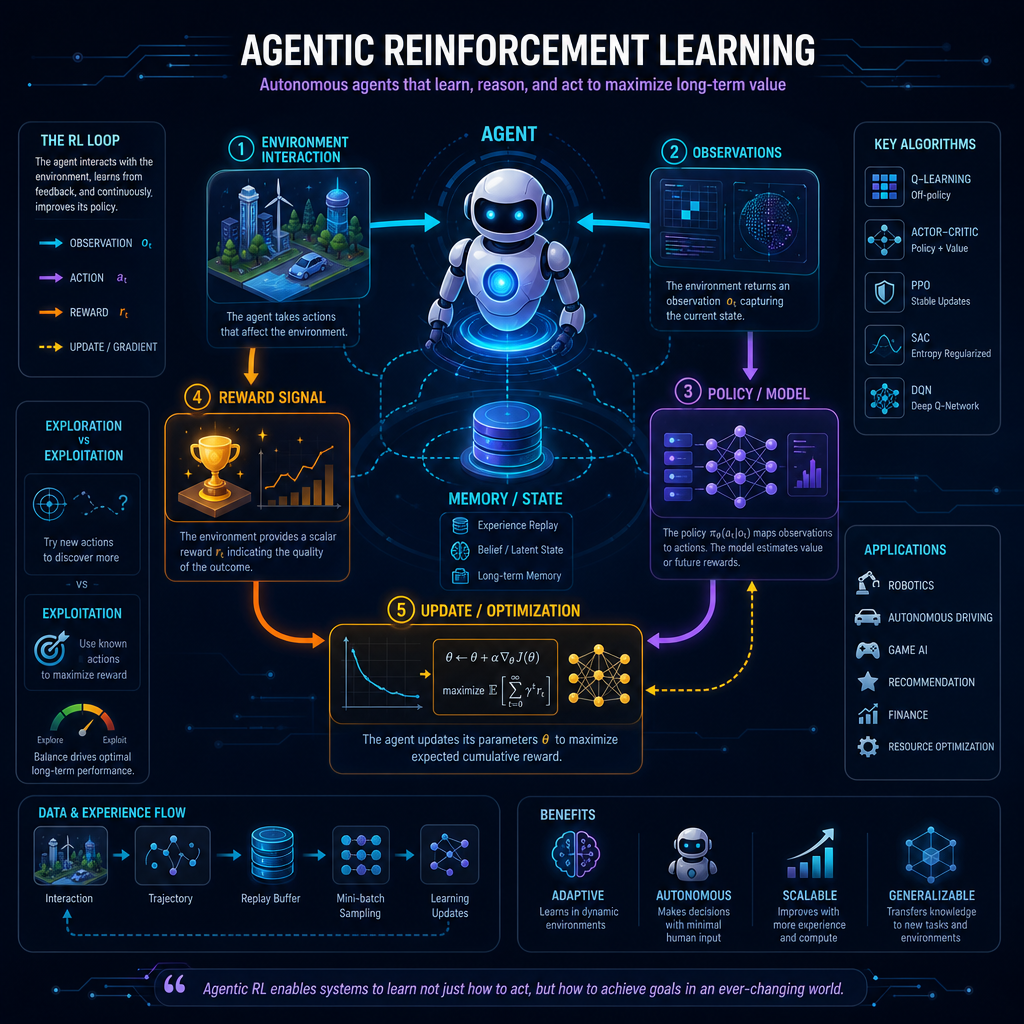
在前两篇文章中,我们讨论了 Agentic RL 的基本概念和算法演进,以及真实世界任务如何被改造成可训练环境。但真正有挑战的任务更是让整个闭环环系统稳定、高效的运行。
以典型的 AIME 数学工具调用 Agent 为例。用户给出数学题,模型首先生成解题计划;中间可能调用 Python Code Tool 计算结果、化简表达式;Python 返回执行结果、发生异常或超时,模型再根据 observation 修正下一步计划;几轮之后,它提交最终答案。SFT 看到的通常是一条静态样本:题目、推理、答案。而 Agentic RL 真正希望训练的是一段交互轨迹里的策略:什么时候该调用工具,调用什么工具,代码失败后如何恢复,环境反馈暴露了哪种中间错误,模型是否能把这些反馈转化成更好的下一步行动。
所以,Agentic RL 的训练对象不是单条回答,而是一段带状态转移的交互轨迹。轨迹不是预先存在的数据,而是当前 policy 在环境里实时采样出来的经验。奖励不是一个静态 label,而可能来自最终答案、过程奖励模型、工具 observation 和 KL penalty。轨迹生成依赖 vLLM[1]、SGLang[2] 这类高吞吐推理引擎;训练依赖 FSDP[3]、Megatron[4] 或 DeepSpeed[5] 这类分布式训练后端;每次 policy update 之后,新的权重还要同步回推理侧,以便执行下一轮 rollout。如果说 SFT 像在固定语料上学习,Agentic RL 更像在一个不断变化的实验场里边采样、边评分、边更新、边同步。本文将对这一整套系统和流程做具体分析。
1. Agentic LLM RL Loop 分析
一个最小的 LLM RL loop 可以写成:
Policy model
-> rollout / tool interaction
-> outcome reward / process feedback
-> logprobs / value / KL
-> advantage / return
-> policy update
-> sync updated weights back to inference engine
-> next rolloutRollout 是让当前模型进入环境,产生自己的经验。对于普通文本 RLHF,它可能只是从 prompt 生成一个 response;对于 Agentic RL,它往往是多轮工具交互,包含 action、observation、环境状态、终止判断等。
Forward pass 是重新计算这些 token 或 action 在当前策略下的概率和 KL penalty。生成时的推理引擎追求吞吐,训练时则需要精确的 per-token logprob。很多系统复杂性,都来自生成阶段和训练阶段使用的并不是同一种计算拓扑。
Reward shaping 是把 outcome、PRM、KL penalty、format reward 等信号合成训练信号。数学和代码任务里的 outcome reward 相对干净,但信号太稀疏;过程奖励更密,但 judge 可能误判;KL penalty 能防止策略漂移,却也可能压制探索。
Advantage 回答的是:这条轨迹比同类尝试好多少。PPO[6] 通常依赖 critic 和 GAE 来计算;GRPO 则对同一个 prompt 采样多条 completion,在组内用 reward 均值和标准差归一化,得到 critic-free 的相对优势。
Update 提高好动作概率,压低坏动作概率。Weight sync 则把新 policy 交回推理引擎,用最新的 model 开启下一轮 rollout。
这也是为什么 Agentic LLM RL 比 SFT 复杂得多——SFT 的数据在训练前基本固定,训练时只需要前向、loss、反向、优化器更新。Agentic RL 的样本来自当前 policy;生成依赖 vLLM / SGLang,训练依赖 FSDP / Megatron;每个 batch 可能要执行 Python、浏览器、数据库、代码仓库或远程沙盒;奖励可能来自多个服务;同一轮训练还可能涉及 actor、critic、reference、reward model、PRM service、tool sandbox 和 inference engine 等诸多模块。总而言之,Agentic LLM RL 实现的背后,是一个持续运转的模型、数据和环境协同系统。
2. Verl 与 SkyRL:两种系统抽象
Verl 和 SkyRL 都在解决 LLM RL 的训练闭环问题,但抽象的主要关注点不同。Verl 更像高性能 LLM RL 训练执行内核,核心是 Controller、WorkerGroup、ResourcePool 和 DataProto;SkyRL 更像面向多轮 Agentic 环境的全栈平台,核心是 Trainer、Generator、Inference Engine、Environment 和 Controller。
两者从不同角度切入了同一个难题。Verl 从分布式计算编排出发,考虑的是 actor、critic、reference、reward model 这些大模型计算节点如何以高吞吐、低冗余、可扩展的方式进行编排。SkyRL 从任务交互和模块化接口出发,让 generator、environment、inference engine、trainer 这些组件设计为能独立替换,并灵活的服务于多轮 agentic 任务。
2.1 Verl:控制流与计算流解耦
Verl 背后的 HybridFlow[7] 论文把 RLHF 抽象成复杂的数据流。传统 RL 里的节点可能只是小型神经网络计算;HybridFlow 里的每个节点都变成了一个分布式 LLM 程序,节点之间还要做多对多的数据重分片。HybridFlow 的关键设计是混合单控制器和多控制器范式:高层 RL 算法由单进程 controller 组织,底层模型计算由分布式 worker 执行。
这种设计带来两个系统层次:
第一层是 control flow。PPO 或 GRPO 的高层顺序仍然可以像普通 Python 程序一样写:rollout、reward、advantage、update。研究者关心算法逻辑,不需要在每一步手写跨 GPU 通信。
第二层是 computation flow。actor generation、actor training、critic forward、reference forward、reward model forward 等计算由 Ray WorkerGroup、FSDP、Megatron、vLLM 或 SGLang 执行。DataProto 是跨 worker 传递、切分、合并的核心数据载体;ResourcePool 则决定 actor、rollout、critic、reward 等角色 colocate 还是 disaggregate。
从用户视角看,driver programming 在顺序执行;从系统视角看,每一步背后都是远端 dispatch、collect、reshard 和并行执行。Verl 的价值就在于把这两种视角在一个系统中融合起来:算法代码保持直观,分布式执行保持高效。
2.2 3D-HybridEngine 的关键优化
HybridFlow / Verl 的 3D-HybridEngine 解决的是 LLM RL 中最困难的资源调度问题之一:同一个 actor 模型既要训练,又要生成。训练态需要参数、梯度、优化器状态和激活;生成态需要推理权重和 KV cache。如果训练引擎和推理引擎各自长期持有一份 GPU 模型副本,就会造成巨大的计算资源冗余浪费。
3D-HybridEngine 的第一层优化是显存分时复用。训练阶段尽量释放或压缩推理侧占用,生成阶段释放训练侧临时状态,让同一组 GPU 在不同阶段承载不同角色。
第二层优化是高效权重重分片。训练使用的 FSDP / Megatron 并行布局与生成使用的 vLLM / SGLang 并行布局不同,更新后的权重必须从训练切片重组到生成切片。HybridFlow[7:1] 专门设计了训练与生成阶段之间的模型参数 resharding,目标是减少模型落盘 / 加载和跨设备通信 IO。论文报告在不同 RL 算法、模型规模和集群设置下,相比基线获得 1.53x 到 20.57x 的吞吐提升。
2.3 SkyRL:Generator 和 Environment 成为一等公民
SkyRL[8] 的入口更靠近 Agentic 任务。它把 RL stack 拆成 Trainer、Generator、Inference Engine、Environment 和 Controller 等模块。Trainer 执行优化步骤;Generator 生成完整 trajectory 并计算 reward;Inference Engine 负责模型推理 rollout;Environment 执行动作、返回 observation 和 reward;Controller 管理组件放置、初始化和执行计划。
SkyRL-v0.1 的文章[8:1]强调,许多 RL 框架把核心组件耦合得太紧,导致修改环境、算法或执行计划时牵一发动全身。SkyRL 试图用清晰的 API 把这些模块拆开解耦:可以独立替换环境、推理引擎、训练后端;可以 colocate 或 disaggregate trainer / generator;可以使用同步 RL,也可以做 async rollout 或 pipelining,实现数倍的性能提升。
2.4 两种抽象的对比
| 维度 | Verl | SkyRL |
|---|---|---|
| 主要抽象 | Controller / WorkerGroup / ResourcePool / DataProto | Trainer / Generator / Environment / Backend |
| 核心关注点 | 分布式 RLHF 计算编排 | 多轮 Agent 任务与训练系统整合 |
| 环境接入 | 可扩展,但任务语义不是最上层入口 | 原生围绕 environment / gym / agent |
| 适合场景 | 底层拓扑、极限吞吐、复杂模型放置 | tool-use、多轮环境、快速实验闭环 |
本文选择 SkyRL 来实现 Retool-RL 数学实验,因为它的整体设计更适用于算法快速迭代,也给中小规模实验提供了足够好的性能和系统灵活性。
3. Retool-RL 实验
本文 Retool-RL 实验基于 OpenClaw-RL[9] 的 tool-call RL 配置,结合 SkyRL 做了实现和优化。核心算法创新是将 On-Policy Distillation[10] 与 Theory of Slow Learning[11] 的 Bridge Thought 融合,并将其适配到 Agentic RL 场景。
传统的 Bridge Thought 多用于预训练或 SFT,而常规 On-Policy Distillation (OPD) 往往依赖更强的外部 teacher 提供 token-level 监督。但在 Agentic RL 中,工具调用的真实反馈(如代码报错、执行输出、人工交互)天然包含了后验信息。利用这些反馈,我们在交互结束后可通过 PRM 自动生成一段简短的 bridge thought,指出模型的偏差与修正建议。
将这段 bridge thought 拼接到 reference 模型的 prompt 中,就能让它在"已知修正方向"的条件下重新计算 logprobs。此时,reference 模型不再只是普通的 KL anchor,而是化身为提供密集监督信号的"后验 teacher"。
这一设计巧妙打通了奖励断层:outcome reward 负责判定"结果对错",而后验 teacher 通过 OPD 指导"过程如何修正",整个流程闭环自洽,完全摆脱了对外部强模型的依赖。
实验的起点是 qwen3-4b-retool-sft,这个模型以 Qwen3-4B-Instruct 为基座,在 ReTool 项目开源的 JoeYing/ReTool-SFT 数据集上做了 3 个 epoch 的 SFT,已具备基本的指令遵循、数学推理和 Python 工具调用格式能力。 优化的目标任务是 AIME 2024 等数学题,Agentic 交互形式是多轮对话,并可以调用 Python Code Tool。得益于上文提到的 GPU 分时复用优化,笔者在单卡 RTX 6000 PRO (96G 显存)上完成了两组实验,其中 Baseline RL 单次实验花费 5 小时左右,而 Hybrid RL 因为 PRM,Bridge Thought 生成和 OPD,单次实验总花费大约 10 小时。
如下表总结,三组实验的核心区别在于信号来源:SFT 信号密但来自静态数据;RL 来自当前 policy 的真实尝试,但奖励稀疏;Hybrid 的目标是两者兼得——on-policy 采样加上更密的局部方向。
| Method | Sampling | Reward / Supervision | 目的 |
|---|---|---|---|
| SFT Baseline | off-policy | dense imitation | 建立工具调用格式与初始能力 |
| Baseline RL | on-policy | sparse outcome | 让模型从自己的解题尝试中学习 |
| Hybrid RL | on-policy | outcome + process reward + token-level teacher signal | 同时获得结果排序和局部方向 |
3.1 实验结果
两组 RL 实验都从同一个 qwen3-4b-retool-sft 模型出发,在 AIME 2024 上对比纯 outcome GRPO 与 PRM + Hindsight / OPD 的 Hybrid RL 版本。两次 step 0 的评估链路略有差异,这里取平均值作为统一 SFT baseline 参考点。从核心指标 pass@8 来看:
| 指标 | SFT baseline | Hybrid RL 最优 | RL 最优 | Hybrid RL 提升 | RL 提升 |
|---|---|---|---|---|---|
| pass@8 | 0.583 | 0.767 (step 6) | 0.667 (step 4) | +31.4% 相对提升 | +14.3% 相对提升 |
Hybrid 的峰值 pass@8 达到 76.7%,相比 SFT baseline 的 58.3% 提升 31.4%,相比纯 Baseline RL 的最优 66.7% 也有约 15.0% 的相对提升。值得注意的是,这些提升是在单卡环境下、通过几个小时训练得到的,这也充分展示了 RL 算法在解决实际问题中的高效和潜力。
结合两个实验的学习曲线,Hybrid 从 step 4 开始突破 70.0%,step 6 达到峰值 76.7%。Baseline RL 的峰值停在 step 4 的 66.7%,此后大多在 60.0%-63.3% 徘徊。Hybrid 在 step 4-12 保持明显优势,但随后也出现退化——最优 checkpoint 应选 global_step_6;若要继续训练,需要配合早停、学习率衰减或更强的稳定化机制。
| Step | Hybrid RL | Baseline RL | Δ |
|---|---|---|---|
| 0 | 0.567 | 0.600 | -0.033 |
| 2 | 0.600 | 0.600 | 0.000 |
| 4 | 0.700 | 0.667 | +0.033 |
| 6 | 0.767 | 0.633 | +0.134 |
| 8 | 0.700 | 0.633 | +0.067 |
3.2 Bridge Thought 案例分析
Hybrid RL 训练里,bridge thought 并不是给模型再写一大段漂亮的 CoT,而是在模型已经走到岔路口之后,补上一句足够短、足够局部、足够可执行的内心提醒。它像把一整段后验信息压缩成一个下一步动作:哪里错了,应该先修哪一处,修完以后该重新验证什么。训练日志里大约 35%-40% 的 trajectory 会触发这类 hindsight 干预;其余 60%-65% 会被判定为不需要干预,直接返回 \boxed{-1}。
最直观的一类例子来自代码调试。训练日志里一条典型的 bridge thought 是这样写的:
"I should define the variable 'x' as a symbol using
symbols('x')before using it in the summation."
这句话的价值不在于它展示了多复杂的数学推理,而在于它把一次工具失败还原成了最小可修复动作:先把 x 放进 sympy 的符号系统,再处理求和。普通 outcome reward 只能在最后告诉模型“这条轨迹错了”,但 bridge thought 直接把工具调用反馈的 traceback 翻译成下一行代码应该怎么写。对 agentic RL 来说,这种信号更接近真正可学习的经验。
第二类例子体现的是工具使用策略,而不是单纯纠错。日志里有一条 hindsight 写得很朴素:
"Instead of calculating the entire product and then taking modulo, I'll apply modulo 1000 after each multiplication."
这句话教的不是某道题的具体结果,而是一种可靠的计算习惯:当目标只是后三位,就不要让中间乘积无意义地膨胀。
第三类例子是几何建模。在原来的 trajectory 中,模型用
"First, set Q at (0, 0) and B at (1, 0). Since QR is at a 60° angle, calculate R's coordinates as (2·cos(60°), 2·sin(60°)) = (1, √3)."
它没有说重新解这道题,而是把修复点固定到最早、可检查的锚点,构建一个稳定可靠的坐标系。
结合以上案例,bridge thought 就像人类做题时真正需要的那句提醒。Outcome reward 告诉模型这条路最后有没有到终点;GRPO 告诉它同一道题的多条轨迹哪条更好;PRM 帮它识别中间步骤是否在推进;bridge thought 则把某一次失败翻译成下一步可执行的修正动作。四者合起来,训练信号才从简单的 0/1 变成了能被模型高效消化的经验。
当然,Hindsight 也有边界:Python 语法错误、明确 traceback、坐标建模缺口、模运算策略这类问题,适合生成短而准的局部提示;但如果错误来自深层的误解,而工具反馈并不明确,强行生成 hint 反而会污染 token-level supervision。在这种情况下,我们需要更多依赖 outcome/PRM 等其他 reward,或者让专家、系统给出更本质的反馈信号。
4. 基于 SkyRL 的 Hybrid RL 实现要点
基于 SkyRL 框架实现 Hybrid RL 时,最值得关注的是它如何把多轮工具交互、过程奖励、后验教师信号和策略更新以模块化的方式实现。
4.1 SkyRL 的训练主循环
从 RayPPOTrainer.train() 看,SkyRL 的主循环可以压缩成下面这条链路:
Prompt batch
-> GeneratorOutput
-> postprocess reward / metrics / masks
-> TrainingInputBatch
-> policy / reference / critic forward
-> KL / advantage / return
-> actor update
-> weight sync这条链路每一步都有明确的数据对象,例如 GeneratorOutput 是采样侧的产物,保存多条 trajectory、以及工具执行错误、终止原因等环境侧统计和采样 metadata;convert_to_training_input() 再把 prompt、response、reward、mask、rollout logprobs 等字段打包成 TrainingInputBatch,并按照 data parallel size、policy mini-batch、critic mini-batch 做 padding 和切分。
这个设计的意义在于:训练器看到的是结构化的数据 batch,而不是某个环境私有的日志格式;环境也不需要知道后面到底跑 PPO、GRPO 还是 Hybrid RL 算法。对 Agentic RL 来说,这一点很关键,因为 rollout 阶段可能包含多工具执行、结果异常、PRM 评分和多轮 observation,而训练阶段最终需要的是可以对齐到 token 的 reward、logprobs 和 mask。
4.2 Agentic Rollout
SkyRLGymGenerator.agent_loop() 是多轮 Agent rollout 的核心。它把模型生成和环境执行组织成一个显式的状态转移过程:
while not done:
output_ids, stop_reason = inference_engine.generate(input_ids)
observation, reward, done = env.step(output_text)
input_ids = input_ids + output_ids + obs_ids
if step_wise:
emit_turn(trajectory_output)每一轮先由 inference engine 生成 assistant action,再交给 environment 执行工具并返回 observation。observation 会被重新编码并拼回上下文,成为下一轮生成的条件。这样,一道数学题不再是一条静态 completion,而是一段 action-observation 交替出现的交互轨迹。
TrajectoryOutput 的字段设计决定了这段轨迹能否被稳定训练。response_ids 保存 policy 真正生成的 token;loss_mask 标记哪些 token 参与 policy loss,避免把 prompt 或 tool observation 当成模型动作来优化;reward 可以承载最终答案分数,也可以承载 step-level 或 token-level 信号。
4.3 Environment 与 Reward 层
以 ReTool 数学环境为例,ReToolEnv.step() 的执行路径可以抽象成:
action text
-> action parser
-> Python executor
-> observation wrapper
-> outcome verifier
-> PRM scorer
-> reward composer模型输出首先被解析成工具调用 action,再通过 Python executor 执行。执行结果、异常、空输出和 timeout 都会被包装成 observation 返回给模型。解析失败时,环境不应该直接中断整条 trajectory,而是返回格式纠错提示,让模型有机会在下一轮修复。这类“可恢复失败”正是 Agentic RL 和普通 outcome RL 的差异之一:模型不仅要学会答对,还要学会读懂环境反馈、修正工具调用、判断何时继续探索以及何时停止。
reward 的组成也不是简单挂一个最终分数。数学任务里的 outcome verifier 负责判断最终答案是否正确;PRM 负责给中间推理和工具使用过程打分;工具调用 shaping 可以鼓励合理调用工具,避免模型退回纯文本猜答案。
4.4 Forward 层
Rollout 阶段已经可以拿到生成 token,但训练时仍然需要重新 forward。原因是推理引擎和训练引擎承担的目标不同:rollout engine 追求高吞吐采样,通常使用 vLLM / SGLang 这类推理引擎;训练 forward 需要精确的 per-token logprob、autograd graph、loss mask 对齐,底层依赖 FSDP / Megatron 等训练后端。
fwd_logprobs_values_reward() 把训练侧的几个模块做了拆分:
| Forward 模块 | 产物 | 在 Hybrid RL 中的作用 |
|---|---|---|
| policy | action logprobs | 当前策略的优化对象 |
| reference / teacher | base logprobs | KL anchor 或 hindsight teacher signal |
| critic | value | PPO / GAE 路径需要,GRPO 路径可以弱化 |
标准 PPO 中,reference model 主要是 KL anchor,用普通 prefix 下的 reference logprobs 防止 policy 偏离初始分布太远。Hybrid RL训练里,这个 reference 路径还可以承担 teacher signal:先从轨迹中提取后延 bridge thought,再构造带后验提示的增强上下文,让 teacher 在 [prompt + bridge-thought + response] 条件下计算 token logprobs。这样得到的不是普通 KL baseline,而是“如果已经知道这条轨迹哪里需要修,teacher 会如何评价这些 token”的后验监督。
4.5 Advantage 层
真正决定算法风格的是 compute_advantages_and_returns()。SkyRL 的好处是,PPO、GRPO、OPD 和 Hybrid RL 的差异可以收敛到这个局部接口里,而不是散落在 generator、environment、forward 和 update 各处。
GRPO 的信号来自同一个 prompt 下的多条采样结果。设一组 trajectory 的 reward 为
它回答的问题是:在同一道题的多次尝试里,哪条 trajectory 更值得学习。这个信号不需要 critic,特别适合数学和代码这类 outcome verifier 相对清晰、但 value function 不一定稳定的任务。PRM 则进一步改变
OPD 的信号来自 token-level teacher logprob。沿用 On-Policy Distillation[10:1] 的视角,teacher 和 student 的差异可以写成 per-token reverse KL:
因此可以把 token-level OPD advantage 写成:
如果 teacher 在 hindsight 条件下更倾向某个 token,这个 token 会得到正向推动;如果 teacher 认为它不合理,则概率会被压低。这正好补充了 GRPO 的局限:GRPO 提供 trajectory-level 排序,OPD 提供 token-level 局部改进方向。
Hybrid advantage 可以看成两类信号的线性合成:
4.6 SkyRL 的模块化价值
回到系统设计,Hybrid RL 能顺利落地,正是因为 SkyRL 把 Agentic RL 分解成几个相对稳定的模块接口。Generator 和 Environment 负责产生带工具 observation 的真实交互经验;Trainer 把这些经验整理成 token-aligned 的训练 batch;forward 层提供 policy、reference、critic 和 teacher 的概率信号;advantage 层决定到底采用哪种 RL 算法。研究者只需要在 reward、forward、advantage 这几个位置注入算法逻辑,底层的高吞吐 rollout、分布式训练和 weight sync 机制仍然可以复用 SkyRL 现有实现。
5. 小结
本文从系统与算法协同的视角,探讨了如何构建高效、稳定的 Agentic RL 训练闭环。
在系统基建层面,我们对比分析了 Verl 与 SkyRL 两种主流的框架抽象:Verl 关注底层计算拓扑,通过控制流与计算流解耦,实现了分布式资源的高效编排与分时复用;SkyRL 关注上层任务抽象,通过 Trainer、Generator、Environment 的模块化拆分,让多轮工具调用与强化学习算法的融合变得极其灵活。两者一起印证了 Agentic RL 的核心系统设计原则:生成、评估、训练分层解耦,异构组件高效协同。
基于 SkyRL 提供的灵活架构,我们完整构建了 Retool-RL 的实际案例,打通了包含工具调用、过程评估与模型更新在内的实验闭环。在此之上,我们验证了新算法带来的显著收益:通过引入过程奖励(PRM)与基于 Bridge Thought 的 Hindsight OPD,我们将环境给出的稀疏执行结果,转化为了稠密且具有局部方向性的梯度信号(Outcome Reward → Process Reward → Token-level OPD)。
这套系统与算法的组合在实验中展现了显著提升:在 AIME 2024 测试中,Hybrid 方案仅使用 10 小时单机训练,就将 4B 模型的 pass@8 从 58.3% 提升至 76.7%,相比纯 outcome GRPO 也获得了约 15% 的相对增益。这充分说明,对于复杂推理任务,高效、灵活的系统基建与更密集、可靠的学习信号,是实现 RL 模型能力跃升的关键。
References
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Hao Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. "Efficient Memory Management for Large Language Model Serving with PagedAttention." SOSP, 2023. ↩︎
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Jeff Huang, Chuyue Sun, Cody Hao Yu, Hao Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. "SGLang: Efficient Execution of Structured Language Model Programs." arXiv:2312.07104, 2023. ↩︎
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Teng Li, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. "PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel." VLDB, 2023. ↩︎
Mohammad Shoeybi, Mostofa Ali Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. "Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism." arXiv:1909.08053, 2019. ↩︎
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. "DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters." KDD, 2020. ↩︎
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. "Proximal Policy Optimization Algorithms." arXiv:1707.06347, 2017. ↩︎
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. "HybridFlow: A Flexible and Efficient RLHF Framework." arXiv:2409.19256, 2024. ↩︎ ↩︎
Tyler Griggs, Sumanth Hegde, Eric Tang, Shu Liu, Shiyi Cao, Dacheng Li, Charlie Ruan, Philipp Moritz, Kourosh Hakhamaneshi, Richard Liaw, Akshay Malik, Shishir G. Patil, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. "Evolving SkyRL into a Highly-Modular RL Framework." Notion Blog, 2025. ↩︎ ↩︎
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. "OpenClaw-RL: Train Any Agent Simply by Talking." GitHub, 2025. ↩︎
Kevin Lu and Thinking Machines Lab. "On-Policy Distillation." Connectionism, 2025. ↩︎ ↩︎
H. Yang, Z.-Q. J. Xu, F. Xiong, and W. E. "A First-Principles Theory of Slow Thinking and Active Perception." ResearchGate, 2026. ↩︎