Modeling Physical AI:
From VLA to World Model

Starting with ChatGPT, the center of gravity of LLM capabilities has experienced a clear shift: first understanding internet semantics through large-scale pre-training, then learning to work in human task formats via instruction tuning, and finally gradually becoming able to complete longer-horizon, more complex actions in the digital world through RL, tool calling, and verifiable tasks.
Echoing the evolution of LLMs, a similar wave is happening in physical AI: VLAs equipped robots with internet-scale semantic understanding for the first time; World Models are now enabling robots to truly understand the world and model how actions change the physical environment.
Over the past few years, Vision-Language-Action Models (VLAs) have become one of the most important paradigms in the field of physical AI. Its core idea is straightforward: fuse vision, language, and action into the same model. By inputting the current visual frame and a natural language instruction, it directly outputs the robot's next action. From OpenVLA and GR00T to the RT and
However, the success of VLA also makes its capability boundaries clear: it is proficient with "nouns" and highly adept at transferring semantic knowledge, but it may not truly understand "verbs". Thanks to massive image-text training, it can instantly recognize Taylor Swift and even accurately push a can of Coke next to her poster. But when you ask it to untie a shoelace, pour a glass of water, fold a soft piece of clothing, or tightly fit a can into the mouth of a cup, the nature of the challenge completely changes. At this point, the robot is no longer facing semantic classification on a screen, but the real physical world—it must handle complex contacts and friction, overcome visual occlusion and object deformation, and constantly fight against geometric constraints and error accumulation caused by continuous actions.
This is also why everyone started paying attention to World Models in 2026: Sora, Veo, Genie, Cosmos, World Labs, JEPA, and DreamDojo pushed this concept to the forefront simultaneously. At the same time, the connotation of a World Model is extremely rich, with widespread applications in video generation, robot control, autonomous driving, and more. But behind these dazzling applications and cutting-edge models, what exactly is a World Model that is truly meaningful for physical AI? We need to go back to the definition of its core problem first.
1. Problem Definition of a World Model
A World Model is not a specific model architecture; rather, it defines a crucial problem: given current observations, internal states, actions, and unobservable variables, the model must predict how the world will change next. Yann LeCun provides the following formalized description of a World Model [2]:
The meanings of the symbols are as follows:
| Symbol | Formal Meaning | What It Means for Physical Robots |
|---|---|---|
| Current Observation | The robot's raw sensor data stream (camera images, depth point clouds, tactile readings, proprioceptive states) | |
| Observation Representation | Compact features extracted from high-dimensional sensory data, stripping away redundant details useless for control and prediction (like background lighting changes) | |
| World State Estimation | The system's internal abstract modeling of the physical world (object spatial poses, velocities, contact relations, the robot's global pose) | |
| Action Plan | Control commands the robot plans to execute (joint control, end-effector pose increments, gripper open/close, mobile chassis control) | |
| Latent Unobservable Variable | Real-world parameters that cannot be read from the current observation but will alter the evolutionary outcome (unknown friction, sudden changes behind occlusions, sensor noise, unpredictable perturbations) | |
Enc() | State Encoder | Maps complex sensory observations |
Pred() | Core Predictor | The true "world dynamics" inference engine: given the current state and proposed action, it deduces "what the physical world will evolve into next" |
Dec() | Decoder | Renders the predicted abstract state back into a pixel video stream (only needed for visual verification; LeCun emphasizes that pixel rendering should be strictly separated from core state prediction) |
We can use the following diagram to represent the architecture of a World Model[3]:
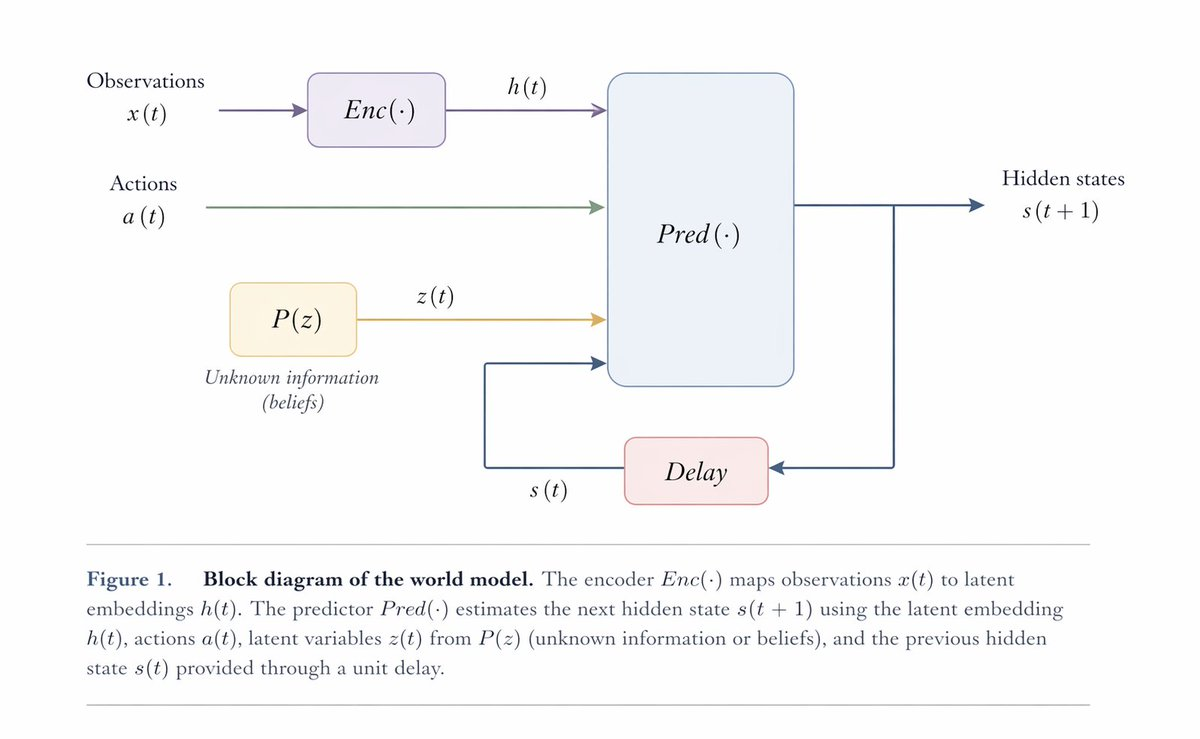
Notice the last line: Dec() is optional, not a prerequisite for a World Model. This seemingly minor detail is actually the center of much debate. Many video generation models look like World Models because they can generate future frames. But if a model merely extends past pixels into a good-looking video, it hasn't necessarily learned state transitions useful for control. For applications like robotics and autonomous driving, the key isn't whether the picture is pretty, but whether the model knows: if the gripper moves left 2 cm, drops 1 cm, and closes 30%, will the can be firmly grasped? If the can nears the cup's mouth but is released too high, will it fall into the cup, get stuck on the rim, or roll onto the table?
Therefore, as emphasized by LeCun's deliberate separation of the two: the core task of a world model is controllable prediction of underlying state evolution; pixel-level rendering is merely an optional Decoder Extension. Rendering capabilities are certainly useful—they allow humans to intuitively verify whether the future "imagined" by the model conforms to physical laws, and provide a visual interface for policy evaluation and debugging. But exactly how much computational capacity a model should invest in reconstructing unpredictable pixel details rather than reserving it for abstract reasoning and control is precisely the most fundamental point of divergence among current major World Model schools of thought.
There is another easily overlooked point: a world model is not purely a visual predictor, but a model about intervention. Ordinary video prediction can simply learn
Thus, a robot World Model must answer at least four levels of questions.
| Level | Core Question | Physical World Example | Value to Control Policy |
|---|---|---|---|
| Representation | What is the underlying abstract state of the current system? ( | Stripping light and shadow from high-dimensional pixels to extract can pose, cup mouth orientation, and gripper aperture | Bridges the sensory gap, providing a denoised, compact, and stable state estimation for the Policy |
| Dynamics | How will the world autonomously evolve given unobservable variables ( | Without action intervention, when will a sliding can stop under the influence of unknown friction ( | Models environmental inertia and physical uncertainty, helping robots predict passive risks |
| Intervention | How will the underlying state ( | Will rigid collision occur if the gripper descends to the target point, or how a specific thrust will change the cup's spatial pose | Enables controllable prediction, supporting counterfactual reasoning, obstacle avoidance correction, and forward planning |
| Value | Among the diverse parallel futures deduced by the model, which trajectory best meets the goal? | Judging based on forward state deduction: the can falling to the bottom of the cup (Reward>0) is significantly better than getting stuck on the rim | Provides action selection scores for the Planner, or serves as RL reward signals in a Training Gym |
Current academic debates over World Model trajectories essentially boil down to differing emphases and trade-offs among these four levels. These divergences touch on the underlying philosophy of modeling physical systems: What information should the model compress and retain? Should forward prediction be performed in pixel space or a highly abstract Latent Space? Should policy networks and world models be decoupled? And the most central point of divergence—does the system actually need to re-render (Dec()) predicted states into human-readable visual frames?
2. Four Classes of World Models
Different answers to these philosophical questions have directly given rise to the four mainstream technological paradigms in the current World Model domain: Generative World Models, Latent Dynamics, JEPA, and 3D Neural Representations.
| Technical Paradigm | Representative Works | Core Prediction Space | Core Strengths | Core Limitations & Challenges |
|---|---|---|---|---|
| Generative Models | Sora, Genie 3, Cosmos, DreamDojo | Observation Space | Extremely easy to scale-up using massive video data; comes with extremely strong rendering capabilities, perfectly fitting data synthesis engines and safe red-blue team evaluations. | Prone to autoregressive drift and physical hallucinations violating common sense; model compute is excessively consumed by image rendering rather than deducing underlying physical causal states. |
| Latent Dynamics | PlaNet, Dreamer Series, TD-MPC | Latent State & Reward | Tailor-made for Model-Based RL; extremely low cost for "in-brain imagination", enabling direct end-to-end training of Policy and Value internally. | Latent space representation heavily relies on the shaping of specific task environments and Reward signals, easily falling into task specialization, with a ceiling on open-world generalization. |
| JEPA | V-JEPA 2.1, LeWM | Learned Embeddings | Resolutely abandons pixel reconstruction loss to avoid wasting compute on unpredictable high-frequency noise; provides pure, task-agnostic self-supervised dynamic priors. | Natively lacks action generation and value judgment modules within the architecture; for real-world deployment, must heavily rely on external planners like MPC (Model Predictive Control) to achieve closed-loop control. |
| 3D Neural Models | NeRF, 3DGS, World Labs Marble | 3D Representation | Provides easily renderable 3D spaces; supports free exploration and seamlessly integrates with mature traditional robot simulation toolchains like Isaac Sim. | Essentially static scene libraries rather than dynamic engines; possess extremely strong spatial encoding but lack native temporal prediction; physical contact and evolution require separate modeling. |
The first class is Generative Models, which is currently the route with the highest public awareness. NVIDIA's Cosmos[4] defines this type of World Foundation Model as a "digital twin of the physical world"; by digesting roughly 100 million high-quality clips meticulously filtered from 20 million hours of raw video, it aims to create a general world prior available for post-training downstream tasks. The strategic advantage of this route is extremely apparent: video, as the most accessible and scalable carrier of physical experience on the internet, allows the model to internalize vast amounts of physical common sense regarding geometry, light and shadow, kinematics, and human behavior without manual annotation. Following this logic, DreamDojo[5] further pushes the large-scale generative paradigm into real-world robot control scenarios. It not only utilizes 44,700 hours of egocentric human interaction video to pre-train a world model, but also creatively introduces continuous latent actions, successfully extracting proxy actions usable for control from real videos without action labels, thereby building a critical bridge between pure visual prediction and physical real-world control.
The second class is the classic model-based RL route. Methods like PlaNet[6], Dreamer[7], and TD-MPC[8] do not predict pixels directly, but predict the future in a compressed latent state, and then train policies and value functions in the model's "imagined" rollouts. Ha and Schmidhuber's early World Models[9] and Hafner's Dreamer series models proved that: if the latent dynamics are good enough, the agent can learn inside the internal model, reducing the cost of interaction with the real environment.
The third class is JEPA. JEPA's viewpoint is more radical: do not predict pixels, predict high-level embeddings. Because the world contains numerous unpredictable details—such as rustling leaves, sensor noise, texture details, and background pedestrians—forcing the model to reconstruct pixel-by-pixel wastes capacity on things that do not help with control. V-JEPA 2.1's[10] work further emphasizes dense spatio-temporal representation: it improves local structure through dense predictive loss and deep self-supervision, making the video self-supervised representation simultaneously support prediction, understanding, and robot planning.
The fourth class is the 3D Representation route. Technologies represented by NeRF[11] and 3D Gaussian Splatting[12] strive to encode physical scenes into 3D spatial structures that can be rendered with high fidelity and explored freely. For embodied AI, 3D geometric priors hold irreplaceable value: the robot's physical interactions (such as collision detection, 6-DoF grasping, spatial planning) are naturally built on precise spatial relationships. However, purely static 3D representations cannot yet be equated with complete world models. They essentially solve novel view synthesis in the spatial dimension, excelling at answering "what does the world look like observed from another perspective"; yet they lack physical dynamics modeling in the temporal and interactive dimensions, unable to answer "how the scene state will evolve if I execute a specific action (like knocking over a cup)".
From a global perspective of embodied AI systems, these four technical routes are not mutually isolated, but are expected to play complementary roles in unified future architectures: Generative Models act as high-fidelity visual simulation engines, injecting massive physical common sense into the model; Latent Dynamics serve as implicit sandboxes for policy training and reinforcement learning, responsible for efficient internal planning deduction; JEPA is positioned as the general perception and predictive representation layer, dedicated to filtering environmental noise and extracting core spatio-temporal states; and 3D Representation constructs the underlying spatial geometry workbench, providing precise 3D spatial constraints for the robot's physical control operations.
Faced with such diverse routes, how to unify them under a standard framework for calling, evaluating, and integrating has become a major engineering topic. OpenWorldLib[13] attempts to provide a systematic solution. Positioned as a "world model method library and unified inference framework", it integrates tasks such as interactive video generation, 3D scene reconstruction, spatial/multimodal reasoning, and VLAs into a standard set of interfaces. Its core abstraction follows a Pipeline -> Operator -> Synthesis / Reasoning / Representation -> Memory hierarchical structure:
- Operator: Acts as the bridge connecting heterogeneous sensory inputs with physical world interactions (e.g., visual streams, instruction control, robot actions), responsible for signal preprocessing and standardization.
- Synthesis / Reasoning / Representation (Core Capability Modules): Correspond to the different capability components mentioned above. Among them, Synthesis is responsible for implicit representation rendering and action synthesis (commonly used in Generative routes); Representation is responsible for explicit 3D expression (commonly used in 3D routes), bridging the physical simulation gap; Reasoning is responsible for complex spatio-temporal and causal deduction.
- Memory: The persistent state center of the world model, recording the sensory flow and action history across multiple rounds of interaction to maintain the agent's temporally coherent cognition.
This unified framework abstraction not only accommodates the differences among the four routes but also makes the evolution from a single model to a multi-dimensional Hybrid Runtime possible.
This perspective also explains why Cosmos[4:1] is important; it's not just a single video model, but organizes data engineering, tokenizers, pre-trained WFMs, post-training examples, and guardrails as a platform. It provides physical AI with customizable and tunable world priors: first learning general dynamics from massive videos, then post-training for specific scenarios like robotics, autonomous driving, and camera control. For technological deployment, this platformization is more valuable than a single model because the real difficulty lies in integrating the world model into a continuously iterative training, evaluation, and deployment pipeline.
DreamDojo[5:1] showcases a version of a World Model closer to robotics needs: based on the Cosmos-Predict model, it introduces continuous latent actions, allowing massive human egocentric videos without action labels to serve as training material for action-conditioned world modeling. The intuition behind this design is quite simple: although human videos lack robot joint labels, there must exist action factors between adjacent frames that cause change. By compressing these action factors out using a latent action model with an information bottleneck, we can turn "watching humans do things" into "learning how actions cause changes".
3. The Advantages and Ceiling of VLA
The success of VLA stems from a very natural paradigm shift: since Large Vision-Language Models (VLMs) have already internalized vast amounts of object knowledge, common sense reasoning, and instruction comprehension capabilities, it is a logical step to integrate "actions" into the same framework. This enables robots, for the first time, to systematically inherit broad internet semantics—not only can they accurately identify coke cans, mugs, drawers, towels, or photos of Taylor Swift, but they can also grasp the general meaning of instructions like "put A on B", "open the cabinet door", or "wipe away the stain". As
However, there is another side to the coin: the internal capability focus of many VLAs is essentially skewed towards Language-Vision-Action, rather than a truly balanced Vision-Language-Action. Strong visual and linguistic priors make them highly adept at aligning task descriptions with visual objects, but when actually outputting "actions", the models often lack an intrinsic understanding of the laws of physical evolution, failing to build sufficiently robust Action-conditioned Dynamics.
This characteristic of being "heavy on semantics, light on physics" draws a distinct capability divide in practical applications:
| Capability Dimension | Areas where VLA Excels (Relying on Semantic Priors) | Areas where VLA is Weak (Relying on Physical Common Sense & Dynamics) |
|---|---|---|
| Noun Generalization | Recognizing new objects, new categories, and understanding Open-vocabulary targets | Distinguishing objects that appear similar but have different physical properties (material, weight, friction) |
| Semantic Generalization | Accurately anchoring high-dimensional language instructions to visual features in physical space | Stably decomposing abstract tasks into continuous low-level control actions that comply with physical laws |
| Verb Generalization | Executing high-frequency basic skills from the training set (Pick / Place / Open) | Handling unseen verbs, complex physical contacts, deformable bodies, or untying knots |
| Environment Generalization | Adapting to static background switches or simple target object replacements | Resisting dynamic disturbances, sudden lighting/viewpoint changes, target pose perturbations, and spatial occlusion |
| Long-Horizon Execution | Performing excellently when supported by explicit high-level state machines | Implementing local error recovery, maintaining prolonged contact states, and immediate replanning after action failures |
4. Experimental Observations: VLA's Limitations in Physical Generalization
Our own simulation experiments clearly corroborated this generalization bottleneck. Powered by an RTX PRO 6000 Blackwell GPU (96 GB), we rigorously stress-tested the actual physical control limits of the
In the ISAAC Sim-based put the can in the mug task[14], which is inherently a very standard foundational Pick-and-place operation, we explicitly injected joint perturbations including Object pose, Container pose, dynamic Distractors, as well as lighting and camera viewpoint shifts. Consequently, the model's success rate across 10 test Episodes plummeted from a cliff-like 100% (under zero perturbations) down to 50.0%. By deeply analyzing its motion trajectories, we found that failure cases were highly concentrated in three typical physical failure modes: failing to maintain a stable spatial transport trajectory after grasping the target; failing to achieve precise alignment and effective release after reaching the container's edge, resulting in the loss of the target object; and the policy becoming completely stalled when facing complex perturbations (with no effective progress throughout).
Illustration of Experimental States and Success/Failure Modes:
Success Example:
| t = 0s: Initial State | t ≈ 3s: Approach/Grasp | t ≈ 5s: Aligned with Cup Mouth | t ≈ 6s Success |
|---|---|---|---|
 |  |  |  |
Failure Mode 1: Lack of stable transport strategy post-grasp
| t ≈ 12s: Can grasped and lifted | t ≈ 24s: Still not transported near mug | t ≈ 29s: Timeout, can far from target |
|---|---|---|
 |  |  |
Failure Mode 2: Reached target vicinity but failed effective release, can lost
| t ≈ 15s: Can near cup mouth | t ≈ 21s: Can pulled away/lost | t ≈ 29s: Timeout, target area empty |
|---|---|---|
 |  |  |
Failure Mode 3: Failed with no effective progress
| t ≈ 6s: No effective action in early stage | t ≈ 15s: Still no progress in mid-stage | t ≈ 29s: Timeout, never successful |
|---|---|---|
 |  |  |
This example is highly representative. "Putting the can in the mug" seems like a simple language objective, but in reality, it encompasses target localization, grasping, transport, geometric alignment with the cup mouth, release height, hold time, and visual occlusion. If the policy only learns "approach the cup," it's not enough. It must know what will happen to the object after contact and release.
Looking further at the local fine-tuning experiment of
These evaluation results do not negate the value of VLA, but clearly demarcate its capability boundaries: when tasks transition from "semantic generalization" deep into genuine "physical and kinematic generalization", purely visual and linguistic priors are no longer sufficient. Robots no longer need models that better understand "nouns", but physical engines that truly understand "verbs".
What humans term "put inside" encompasses complex control over friction, object deformation, spatial obstacle avoidance, and continuous posture in the real world. VLA's core limitation is that it's essentially an imitation learner "mapping images to actions", rather than a causal deduction model "understanding how actions alter future states". Once out of the training distribution—for example, swapping a rigid block for a soft sponge, or a wide-mouth bowl for an extremely narrow cup mouth—although the "semantics" of the task remain unchanged, the underlying "physical characteristics and contact dynamics" are completely different. Faced with such changes, a pure imitation policy lacking physical deduction capabilities will become extremely fragile.
5. From VLA to World Model
Based on the preceding analysis, the core limitation of the VLA paradigm has become apparent: it lacks modeling of the causal relationship between actions and future physical states. This is exactly the fundamental shortcoming that World Models aim to fill.
VLA's native paradigm is "Instruction Following"—the model maps current observations and language goals end-to-end into action outputs. This makes it thrive when handling open-vocabulary goals, long-horizon task decomposition, and object semantic generalization. However, the real difficulty in robot control often lies not in "understanding what the goal is", but in "understanding whether the world will evolve toward the goal state as expected after executing this action". To this end, World Models reframe the core of the problem from "Action Prediction" to "Future Prediction": given the current state and candidate actions, deduce the world's subsequent evolutionary trajectory, and use this as the cornerstone for evaluating candidate policies, forward planning, or training action policies.
The underlying logical differences between these two paradigms can be summarized as follows:
| Paradigm | Core Question | Typical Interface | Core Advantages | Limitations & Challenges |
|---|---|---|---|---|
| VLA | Given current observations and instructions, what action should be taken? | Semantic reasoning, open-vocabulary goal understanding, expert trajectory imitation | Out-of-distribution physical changes, complex contact handling, long-horizon error accumulation, and failure recovery | |
| World Model | How will the physical world evolve after a given action intervention? | Internalization of physical laws, prediction of action consequences, generation of counterfactual experiences | Compounding errors (long-horizon drift), model physical hallucinations, action-conditioned controllability |
This is also the core logic behind Embodied AI's evolution from VLA to World Model: moving from "blind action imitation" to "causal deduction based on action consequences". Specifically, World Models are expected to play four critical roles in future robotic systems:
First, Evaluator. Faced with identical initial observations and task goals, VLAs often output multiple candidate action chunks. The World Model can "roll out" these candidate actions forward into multiple future trajectories, which are then scored by VLM reward functions, rule checkers, or geometric constraint modules. WorldGym[15] fully validated this approach: starting from a real initial frame, it runs the VLA policy within the World Model and utilizes the VLM to evaluate the results, ultimately obtaining feedback highly consistent with real-world testing. This mechanism successfully transforms costly physical trial-and-error into low-cost "in-brain deductions".
Second, Planner. Policy models do not need to output the final solution in a single step; instead, they can first propose several short-horizon exploratory plans, hand them over to the World Model to predict their respective physical consequences, and thereby filter out the trajectory that best aligns with the goal and poses the lowest risk for execution. In this process, the World Model is not strictly required to achieve pixel-perfect rendering, as long as it possesses sharper physical intuition than blind heuristic policies when identifying "critical failure modes" (e.g., collisions, drops).
Third, Trainer. Given that interactive data from real robots is extremely expensive, "imagined rollouts" inside the World Model can directly serve as high-fidelity virtual environments for Reinforcement Learning (RL) or Test-time Adaptation. World-Gymnast[16] builds on this by leveraging imagined trajectories and VLM reward signals for closed-loop RL training, significantly raising the policy's ceiling. Moreover, when coping with physical distribution shifts, research like WorldAgen[17] upgrades the world model from a "static pre-trained engine" to a "dynamically updating environment". By collecting only a tiny amount of interaction data at the deployment site, robots can use lightweight technologies like LoRA to conduct Test-Time Training on the World Model, allowing it to rapidly internalize the physical dynamics of the new environment and subsequently guide more precise adaptive planning.
Fourth, Data Engine. World Models can freely synthesize novel camera viewpoints, complex backgrounds, target poses, and even dynamic distractors. They can even construct Counterfactual Events out of thin air from real suboptimal trajectories: "If the gripper had been lowered by two more centimeters and released half a second later back then, would the task have succeeded?" This continuously synthesized long-tail failure recovery and counterfactual interaction data is precisely the scarce resource that traditional Teleoperation critically lacks and struggles to obtain at low cost.
In such a highly self-consistent closed loop, the World Model provides a safe, low-cost sandbox for physical trial-and-error. The VLA is responsible for capturing and integrating human semantic intent into the system; the World Model is responsible for deducing the physical consequences of action interventions; the reward/verifier assesses the merits of future trajectories; and real physical interaction data is continuously used to calibrate and iterate the models. Only when these modules organically fuse can the foundation model of the physical world stride towards solid physical generalization.
6. From World Model to Executable Policy
Building upon this foundation, academia and industry are moving toward a new paradigm: deeply integrating the World Model with the Policy, achieving joint modeling of video prediction and action generation. Nvidia's GEAR team formally designated this type of architecture as the World Action Model (WAM) in DreamZero[18], and similar ideas have been widely reflected in a series of cutting-edge works such as Genie Envisioner[19], GR-2[20], and Cosmos Policy[21]. When a model not only predicts the physical world's future state but simultaneously predicts "what intervention actions are required to realize this future," it leaps from being a mere environmental observer to becoming an executable closed-loop control policy.
From a formal definition perspective, the traditional VLA paradigm can be expressed as:
That is, given historical visual observations
By contrast, the WAM paradigm reframes this as a Joint Modeling problem:
Here,
This joint modeling brings about a fundamental change: video prediction serves as Dense World-model Supervision, forcing the model to internalize the physical common sense of "how the world will change" through every frame in the trajectory. Meanwhile, action prediction naturally regresses into an Inverse Dynamics problem—to logically evolve the current visual state into the predicted future, what physical interventions should the robot exert?
In other words: VLA learns "when seeing this state, what did the expert do"; a pure World Model learns "after executing an action, how will the world evolve"; whereas WAM further internalizes the causal relationship—"if the physical world should evolve like this, how must the robot's body act to make it happen".
The most ideal WAM does not merely output an action sequence; internally, it generates a highly constrained, executable future. When it "imagines" a gripper approaching a cup, the output continuous action sequence must precisely correspond to the approaching trajectory in real physical space. When it "imagines" a can being inserted into a cup mouth, the action sequence must strictly encompass physical contact processes such as transport, geometric alignment, release, and stable holding. Consequently, action is no longer a macroscopic abstract concept, but an action plan strictly constrained by the predicted future state and physical common sense.
DreamZero Representative Case
NVIDIA's recently proposed DreamZero[18:1] is currently the benchmark work best illustrating how a World Model deeply integrates with a policy. It abandons the piecemeal route of "first training a world model, then attaching an inverse dynamics model (IDM) or planner externally," directly extending a 14-billion parameter video Flow Matching DiT into a Joint Video-Action Denoiser. By introducing video Tokens and action/state Registers into the same Transformer sequence, DreamZero achieves synchronous autoregressive prediction of future vision and future actions.
In terms of engineering and architecture, DreamZero has several highly inspiring core designs:
First, Native inheritance of large-scale video priors. Its Backbone directly utilizes a pre-trained Image-to-Video (I2V) diffusion model (such as Wan2.1-I2V-14B[22]), taking current and historical visual observations, language instructions, and robot Proprioceptive State as joint conditional inputs. This exempts the model from learning physical laws from scratch, directly inheriting the light/shadow, geometry, and collision common sense contained in massive internet videos.
Second, Joint Prediction within a unified architecture. DreamZero deeply fuses and mutually constrains video prediction and action generation during the training phase. The predicted video must conform to physical logic, and the generated actions must precisely cause the state evolution in the video, thereby achieving strong alignment between vision and control. Furthermore, to enable the massive diffusion model to run in real-time on a robot, the team introduced the innovative DreamZero-Flash mechanism: during training, it cleverly separates the noise-adding processes for video and action, deliberately keeping the video end in a highly noisy "blurry" state, forcing the model to learn that "even if the imagined future frame in its mind is still blurry, it can steadily extract clear, precise physical actions." This design vastly compresses the diffusion steps required for inference, boosting real-control frequency significantly to about 7Hz, thoroughly crossing the threshold for real-time closed-loop control.
Third, Error backfilling based on real observation closed-loops. To solve the long-horizon Drift problem common in autoregressive generation, DreamZero introduced a "real-world refresh" mechanism. During real-world deployment, after executing each Action Chunk, the system forcibly replaces the prediction frames "imagined" by the model in the KV Cache with new observation frames captured by real cameras, completely cutting off error accumulation in closed-loop control.
DreamZero's performance fully corroborates the WAM paradigm's disruptive potential in physical generalization. It proves that robots do not need to rely on massive, high-cost real-world action data to create the "magic" of generalization; they only need the guidance of powerful video priors for action generation. In evaluations on the AgiBot platform involving entirely Unseen Tasks like "untying shoelaces" and "ironing clothes," DreamZero demonstrated outstanding Zero-shot Generalization capabilities, far outperforming existing pre-trained VLA models (like GR00T and
Joint Denoising
Experimental Comparison: How WAM Models Breakthrough Physical Generalization Limits
To verify the enhancement of physical generalization capabilities by the World Action Model (WAM), we conducted comparative evaluations on the DreamZero policy (based on large-scale video priors) in the exact same challenging scenario as the aforementioned
Illustration of DreamZero's Successful Execution Flow:
| t = 0s: High Perturbation Initial State | t ≈ 6s: Precise Grasp & Stable Transport | t ≈ 11s: Geometric Alignment & Successful Release |
|---|---|---|
 |  |  |
This comparison perfectly illustrates the core advantage of WAM. VLA's failure lies in the fact that when lighting and object geometry experience changes beyond the training distribution, surface-level imitation of "vision-action" alone cannot maintain stable contact dynamics. By contrast, DreamZero's success stems from the model having internally internalized the causal laws of "after executing an action, how will the physical world evolve". Video priors bestow it with profound intuition regarding contact, friction, and 3D geometric constraints, allowing it to deduce control trajectories compliant with physical laws even under extreme perturbations, truly pushing the robustness of Physical AI to new heights.
8. The Data Flywheel of World Models
If one only understands World Models as 3D video generation, then their value is merely confined to design and entertainment. But for vital physical AI applications like robot control and autonomous driving, their core significance lies in reshaping the entire R&D lifecycle. As NVIDIA scientist Jim Fan proposed at Sequoia AI Ascent, Physical AI is experiencing "The Great Parallel," directly replicating the successful trajectory of LLMs [23]:
| LLM Path (GPT-3 to o1) | Physical AI Parallel Path (VLA to WAM) |
|---|---|
| Next-token Prediction: Pre-training linguistic rules | Next-state Prediction: Pre-training physical intuition with massive video data |
| SFT (Supervised Fine-Tuning): Aligning task formats and human preferences | Action Fine-Tuning: Aligning robot-specific physical hardware and tasks |
| RL (Reinforcement Learning): Evoking deep reasoning capabilities | RL in World Models: Doing RL and planning within world models |
| Data Flywheel: From user interaction and tool feedback | Data Flywheel: Fusion optimization based on real deployment, egocentric video, and world model imagined data |
The success of RL for LLMs relies on scalable environmental feedback (like code compilers or math evaluators), and what robotics previously lacked most was precisely this kind of scaled feedback loop—we cannot possibly build millions of physical robots just to run million-concurrency RL. The fundamental breakthrough of World Models is acting as a purely data-driven Neural Simulator. It compresses the common sense of the physical world into the model, so real-world trial-and-error is migrated to cloud-based Imagined Environments, becoming an infinitely parallel, replayable, and low-cost trial-and-error process.
Under this framework, the construction of the robot data flywheel undergoes a shift from "human-collected" to a "frictionless flywheel", primarily relying on four sources of experience:
| Source of Experience | Analogy to LLM | Advantages | Limitations |
|---|---|---|---|
| Human / Egocentric Video (e.g. Eagle Scale) | Pre-training massive corpus | "Tesla FSD-level" scalability, extremely large scale (tens of millions of hours), covering all physical long-tail scenarios | Lacks precise action labels, existence of Embodiment Gap |
| Teleop Demonstration / Wearables | High-quality SFT demonstrations | Action labels are absolutely precise, 1:1 aligned with target robot | Extremely high cost, hard to cover failure recovery data |
| World Model Rollout (e.g. DreamDojo) | Auto-sampling in RL environment | Compute is the environment, enables counterfactual reasoning, achieving low-cost, million-concurrency trial-and-error | Limited by the world model's own accuracy errors, requires real data calibration |
| Real Deployment Logs | Online user feedback (RLHF) | Absolutely real physical distribution, can expose long-tail and fatal defects | Deployment costs are extremely high, strict safety requirements, high difficulty in data cleaning |
In this Tesla FSD-style closed loop: we first utilize massive Egocentric Video for large-scale pre-training, allowing the model to autonomously acquire gravity, geometry, and common sense; next, we use a small amount of extremely expensive Teleop data as a "primer" for action fine-tuning, cold-starting the robot's base policy; subsequently, we put the policy into World Model Rollouts, using GPU compute to replace physics engines and real environments, completing large-scale concurrent RL in "imagination"; finally, we collect Real Logs in actual deployments to calibrate errors, enabling the updated World Model to generate more realistic simulations.
Ultimately, robots will no longer rely on humans wearing cumbersome sensory equipment to perform expensive teleoperation demonstrations time and again. By organically fusing massive passive human observation data, low-cost imagined data, and core real machine data, physical AI will truly welcome its "Large Model Moment"—an exponentially evolutionary path toward physical AGI.
9. Conclusion
The core significance of a World Model is never merely generating more realistic videos, but accurately deducing how actions will alter the physical world. Only when this capability to predict the future can be scored by evaluators, called by planners, internalized by policy training grounds, and calibrated in real physical environments, does it truly transform from a simple visual generation engine into the indispensable Neural Simulator for physical AI.
VLA bridged the gap of semantic cognition, letting robots "understand instructions and recognize everything"; World Models, in turn, complete the puzzle of causal deduction, endowing robots with the physical imagination to "trial-and-error in their minds". From VLA based on imitation learning, to World Models building physical forward predictions, and finally to WAM (World Action Model) deeply uniting state evolution and action generation, physical AI is undergoing a profound paradigm leap. Following this evolutionary trajectory extremely similar to LLMs, the foundation models of physical AI are firmly marching from unidirectional actuators toward closed-loop agents that integrate perception, imagination, deduction, and action.
References
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, et al. "
: a Vision-Language-Action Model with Open-World Generalization." arXiv:2504.16054, 2025. ↩︎ ↩︎ Yann LeCun. "A Path Towards Autonomous Machine Intelligence." OpenReview, 2022. ↩︎
Vai Viswanathan. "WTF is a World Model?" X, 2026. ↩︎
NVIDIA. "Cosmos World Foundation Model Platform for Physical AI." arXiv:2501.03575, 2025. ↩︎ ↩︎
Yingdong Hu et al. "DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos." arXiv:2602.06949, 2026. ↩︎ ↩︎
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, et al. "Learning Latent Dynamics for Planning from Pixels." International Conference on Machine Learning, 2019. ↩︎
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. "Dream to Control: Learning Behaviors by Latent Imagination." International Conference on Learning Representations, 2020. ↩︎
Nicklas Hansen, Xiaolong Wang, and Hao Su. "Temporal Difference Learning for Model Predictive Control." International Conference on Machine Learning, 2022. ↩︎
David Ha and Jürgen Schmidhuber. "World Models." arXiv:1803.10122, 2018. ↩︎
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, et al. "V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning." arXiv:2603.14482, 2026. ↩︎
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, et al. "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis." European Conference on Computer Vision, 2020. ↩︎
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. "3D Gaussian Splatting for Real-Time Radiance Field Rendering." ACM Transactions on Graphics, 2023. ↩︎
Bohan Zeng, Daili Hua, Kaixin Zhu, et al. "OpenWorldLib: A Unified Codebase and Definition of Advanced World Models." arXiv:2604.04707, 2026. ↩︎
"sim-evals", GitHub. ↩︎
Julian Quevedo, Ansh Kumar Sharma, Yixiang Sun, Varad Suryavanshi, Percy Liang, et al. "WorldGym: World Model as An Environment for Policy Evaluation." arXiv:2506.00613, 2025. ↩︎
Ansh Kumar Sharma, Yixiang Sun, Ninghao Lu, Yunzhe Zhang, Jiarao Liu, et al. "World-Gymnast: Training Robots with Reinforcement Learning in a World Model." arXiv:2602.02454, 2026. ↩︎
Chi Wan, Kangrui Wang, Yuan Si, et al. "WorldAgen: Unified State-Action Prediction with Test-Time World Model Training." Proceedings of the AAAI Conference on Artificial Intelligence, 2026. ↩︎
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, et al. "World Action Models are Zero-shot Policies." arXiv:2602.15922, 2026. ↩︎ ↩︎
Yue Liao, Pengfei Zhou, Siyuan Huang, et al. "Genie envisioner: A unified world foundation platform for robotic manipulation." arXiv:2508.05635, 2025. ↩︎
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, et al. "GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation." arXiv:2410.06158, 2024. ↩︎
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, et al. "Cosmos policy: Fine-tuning video models for visuomotor control and planning." arXiv:2601.16163, 2026. ↩︎
Team Wan. "Wan: Open and Advanced Large-Scale Video Generative Models." arXiv:2503.20314, 2025. ↩︎
Jim Fan. "Robotics’ End Game: Nvidia’s Jim Fan." YouTube, April 30, 2026. ↩︎